
开篇
基本表格不同于透视表格的复杂,只有行和列的区分,表头的结构也较为简单,接下来来看下关于基本表格的表头结构相关部分。
场景树相关
VTable 是以场景树的形式管理表格各个模块的,对于基本表格的表头,主要是涉及到了下面几个节点:
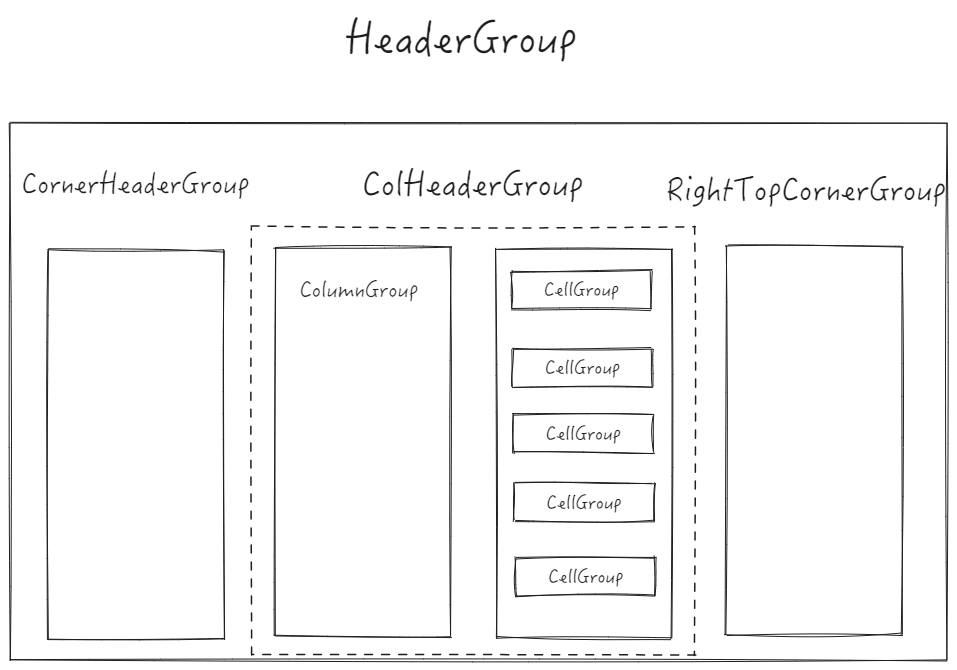
- colHeaderGroup
列表头节点:负责管理整个列表头,表头部分不会随着滚动而改变位置;
- columnGroup
列Group:每一列为单独的一个容��器,基本上每列都会有着自己的样式配置;
- cellGroup
单元格节点:每一个单元格都会单独维护一份,内部包含了需要绘制的所有图元节点;
- rightTopCornerGroup
右侧冻结列表头: 当配置右侧冻结列的时候,对右侧的冻结列表头单独维护一份;
- cornerHeaderGroup
左侧冻结列表头:维护左侧冻结列的表头部分,相当于角表头;
布局模块
基本表格表头布局相关的模块单独维护在 SimpleHeaderLayoutMap 类中,内部包含了诸多布局相关的逻辑以及辅助函数等,最重要的是下面几个子模块。
原始列定义存储
关于原始的列定义单独在 interProps 上维护了一份,而在 LayoutMap 中又单独维护了一份 _columns,不同的点在于,对于树形结构,_columns仅仅会维护一份叶子节点,该字段主要是用于获取列数以及获取列定义的操作。
为了达成列隐藏的功能,VTable 内部隐藏的节点不会放在 _columns 中,而是单独存放在 _columnsIncludeHided 中,这里面包含了所有的叶子节点。
维度树
对于这样一个多级表头,可以以一个维度树的形式来维护。不过在基本表格内部,维护一个树形结构的代价太大了,VTable 为此采取了另外一种方案。

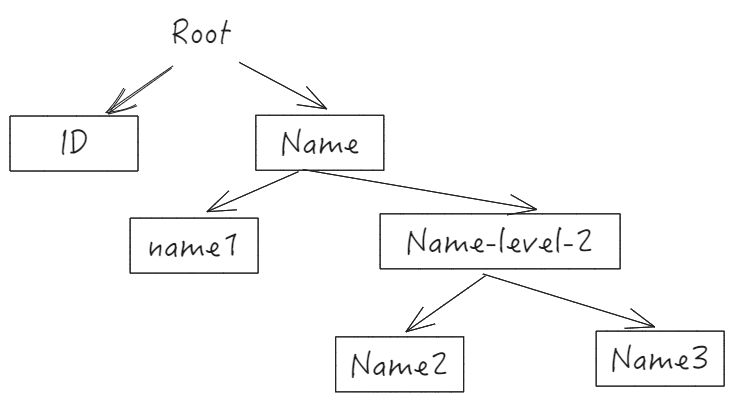
树形结构替代方案
既然树形结构实现难度过大, 那么有什么办法能够降低处理树形结构的复杂度呢?VTable 内部是这么解决的:
对于表头,将列的定义进行拍平,为每一列定义一个索引,建立索引与列定义的映射表;同时以表格的布局生成一份二维的表头 ID 矩阵,在对应的行列处生成对应的索引,使用行列号获取id,再根据 id 就能获得对应单元格上的列定义。
拍平后的列定义映射表维护在 layoutMap._headerObjectMap 中,二维的数据索引维护在 layouMap._headerCellIds 中。
我们以上面的树形结构为例,
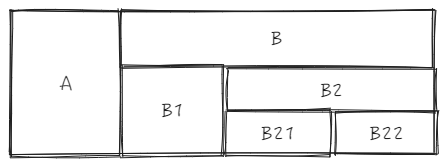
_headerCellIds 长这样
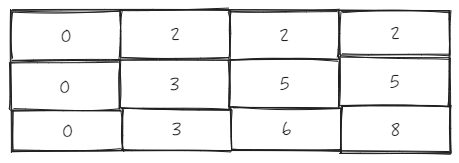
对应的 _headerObjectsMap 映射表:

通过将树形结构进行解耦,拆成每行每列对应的 id 的数据索引表 和 id 对应的列定义的映射表,除了需要在表头结构发生变化额外对表头ID矩阵进行维护之外,在列定义的获取的简便性和存储方面的性能都是远胜于直接存储树形结构。
合并单元格范围缓存
在基本表格表头存在合并表头的情况下, 会有根据行列号获取当前单元格是处在哪个范围内的需求,如果频繁的去根据原始结构进行判断,将会造成极大的性能浪费,为此 LayoutMap 内部存储了一份合并单元格范围的缓存_cellRangeMap,该映射表以 ${col}_${row} 为key,当前单元格所处的 cellRange 为 value。
后续如果有需要根据行列号获取所处范围的需求,便可以直接根据该映射表去获取。需要注意的是当表头位置拖拽后,这个缓存的行列号已不准确,需要进行重置。
模块生成
上面�介绍了关于 LayoutMap 中几个重要的模块及其用法,下面来看下各个模块在初始化的时候是如何生成的:
表头ID矩阵
由于表头ID矩阵和表头定义映射的生成都是在同一个函数 _addHeader中完成的,所以直接上手去理解该功能函数难度较高,这里先将两部分逻辑拆开来看,先来看下关于数据索引表部分的生成:
以上图的树形表头举例,来看下 _headerCellIds 的生成逻辑。
const columns = [ { field: 'id', title: 'ID', }, { title: 'Name', columns: [ { field: 'name1', title: 'name1', }, { title: 'name-level-2', columns: [ { field: 'name2', title: 'name2', }, { title: 'name3', field: 'name3', } ] } ] } ];
功能简化
这里是简化后的关于 _headerCellIds 的生成逻辑:
// packages\vtable\src\layout\simple-header-layout.ts
const _columns = [];
let seqId = 0;
const _headerCellIds = [];
function _addHeaders(row, column, roots) {
const rowCells = _newRow(row);
column.forEach(hd => {
const col = _columns.length;
const id = seqId++;
for (let r = row - 1; r >= 0; r--) {
_headerCellIds[r] && (_headerCellIds[r][col] = roots[r]);
}
rowCells[col] = id;
if (hd.columns) {
_addHeaders(row + 1, hd.columns, [...roots, id]);
} else {
_columns.push(hd);
seqId++;
for (let r = row + 1; r < _headerCellIds.length; r++) {
_headerCellIds[r][col] = id;
}
}
});
}
单行索引生成
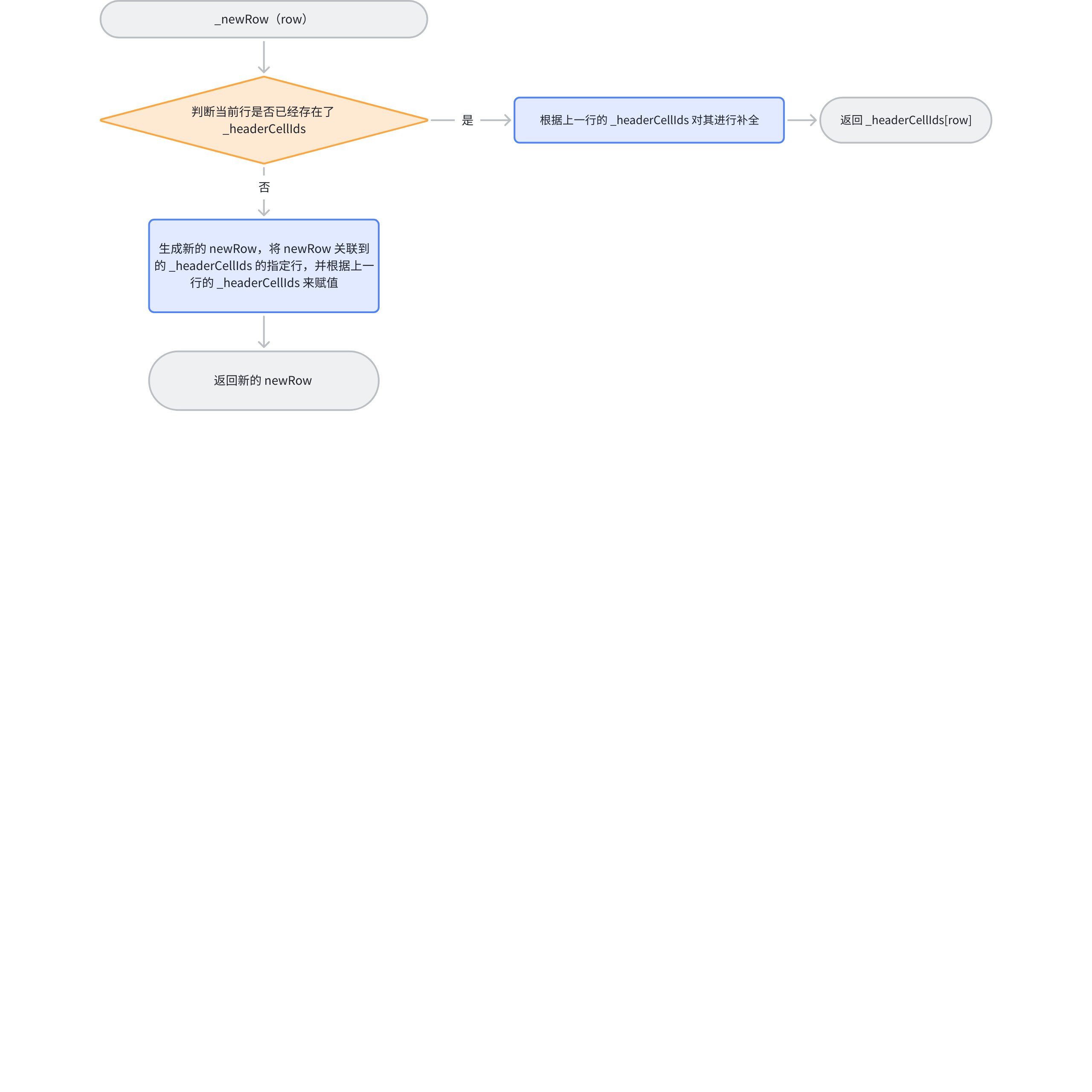
在具体对逻辑进行解析之前,先来看下是如何通过行号对当前行的 rowCells 进行关联的:
在生成行的时候,会分两种情况:
-
如果当前行已经存在了,会根据上一行的数据,对当前行进行补全,同时返回当前行的地址;
-
如果当前行不存在,会生成 newRow ,将 newRow 关联到 _headerCellIds[row] 上,再将上一层的信息进行同步到 newRow 中,返回 newRow 的地址,这样就能在对 rowCells 修改的时候,同步修改到
_headerCellIds中。
_headerCellIds 变化
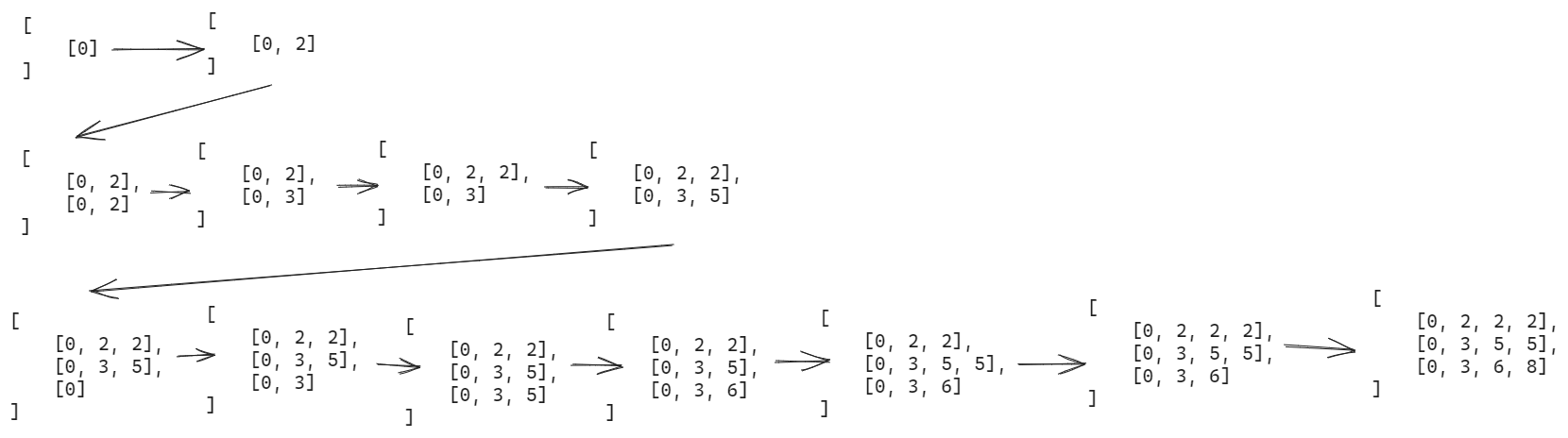
这里是 _addHeaders 过程中,_headerCellIds 发生的变化:
生成流程
可以看到,最后生成的 _headerCellIds 的列数是由 columns 树的广度决定、而行数则是由树的深度决定的。
生成过程主要是通过深度优先遍历,在遍历列之前,会先生成 rowCells 与 _headerCellIds 进行关联。
在遍历列的过程中,处理当前节点前,如果遇到上层同一列有节点的情况下,会将上层同一列的节点进行更新。
在处理完上一层之后,对本行本列的索引进行更新。
如果存在子树,会继续递归,更新roots,roots 表示的从根节点到当前节点的路径。
如果没有子树,会对本列下方的节点进行更新,随后进入下一次遍历。在递归完成后,代表着 _headerCellIds 的更新完成了。
表头映射
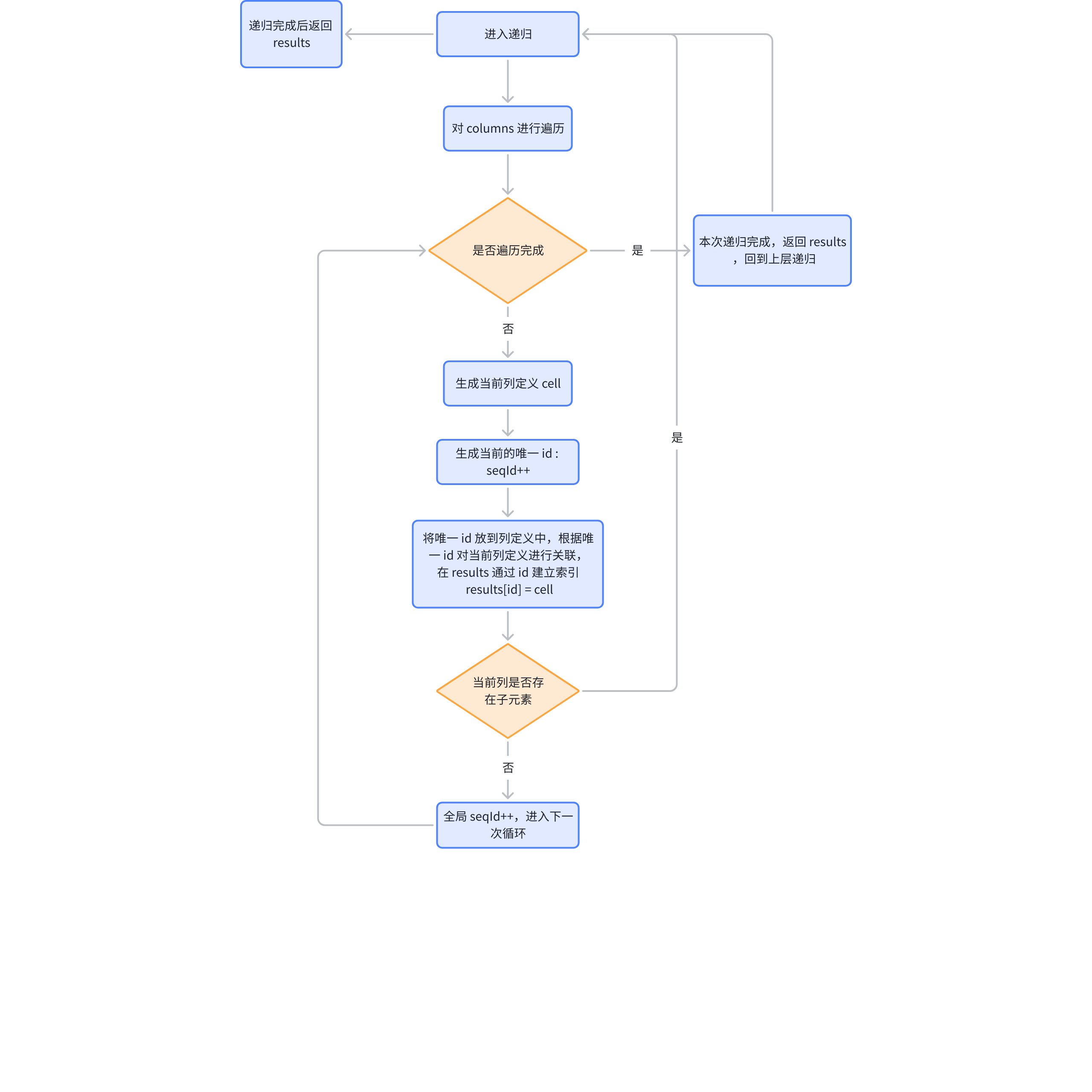
表头映射相对于表头ID矩阵的生成比较简单,就是一个递归的过程。
// packages\vtable\src\layout\simple-header-layout.ts function _addHeaders(row, column) { const results = []; column.forEach((hd) => { const id = seqId++; const cell = { id, title: hd.title ?? hd.caption, ... }; results[id] = cell; if (hd.columns) { _addHeaders(row + 1, hd.columns).forEach((c) => results.push(c)); } else { seqId++; } }); return results; }
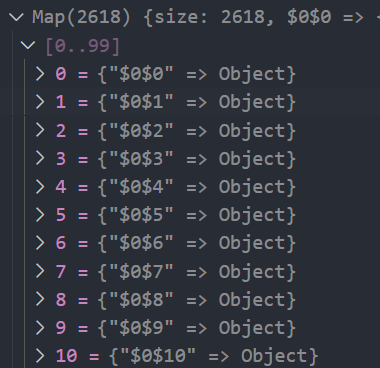
递归完成后的 _headerObjectsIncludeHided 长这样:
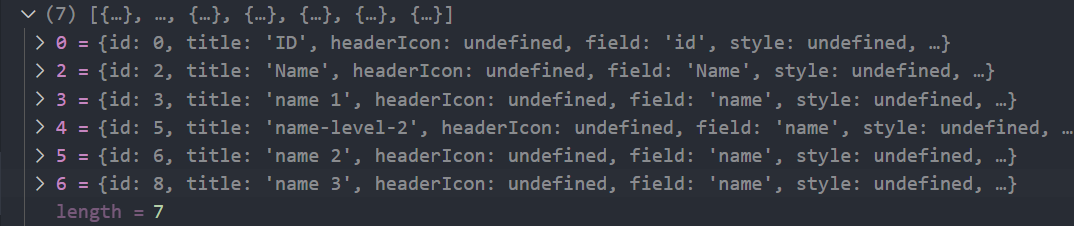
随后通过 reduce 进行处理,生成 _headerObjectMap
// packages\vtable\src\layout\simple-header-layout.ts this._headerObjectMap = this._headerObjects.reduce((o, e) => { o[e.id] = e; return o; }, {});

结语
基本表格的结构划分相对于透视表来说会更简单,只需要维护列表头即可。
表头结构被划分为了几个重要的模块:
-
_headerCellIds:负责管理当前行列号下对应的列定义的索引;
-
_headerObjectMap:列索引与列定义的映射表;
-
_columns:维护表头结构的叶子节点;
本文档由以下人员提供
taiiiyang( https://github.com/taiiiyang)