
开篇
常用的表格组件库都是基于 DOM 去实现,很少会有基于 Canvas 去渲染的表格组件库。而 @Visactor/VTable 提供了基于 Canvas 渲染的表格组件库。本篇将从各种功能和交互的实现入手,来看下 ListTable 是如何去依靠 Canvas 提供的能力去实现类似原生 DOM 的操作的。
ListTable 外部依赖
在对 ListTable 进行细节分析前,有必要先提下 ListTable 的外部依赖 VRender。VRender 是由 ByteDance 提供的一款可视化引擎,通过将 Canvas 的渲染图形的过程抽象成 Group 和 Stage 进行管理,可以通过配置的形式在 Canvas 内部快捷的生成不同的图元。Group 可以理解成多个图元��的组,Stage 则对所有图元和 Group 进行管理,在下文中会经常提到这两个部分。
ListTable 架构
首先来了解下大致的架构,ListTable 基本架构可以划分为下面几个模块
-
渲染引擎:Scenegraph 场景树。表头的移动、图形渲染、单元格宽高计算等都包含在场景树中;
-
渐进式生成:SceneProxy 模块是 Scenegraph 下的一个子模块,定义了场景树初始化的生成、维护场景树在初始化时生成的最大行列值、同时负责滚动渐进渲染的逻辑;
-
状态管理:StateManager 处理表格状态,hover、select 在 ListTable 都是以数据的形式存在的,在 state 发生改变的时候,会去触发 Scenegraph 重新渲染图表;
-
事件系统:EventManager/EventHandler 处理交互事件;
-
布局管理:LayoutMap 表格核心布局模块。通过配置生成行列表头、维护单元格信息;包括树形表格、多级表头的信息计算,都是在 Layout 中;
-
布局计算:通过 colWidthsMap/rowHeightsMap 维护行列宽高数据;
-
样式系统:通过 theme/style 相关模块管理样式;
-
数据管理:通过 DataSource 实现对 records 的托管,包括数据的增删改查、排序、聚合等逻辑处理;
��如果能够理解上面的几个模块,就能理解 ListTable 的大致工作流程了。
基本表格布局初始化
基本表格不同于透视表的复杂,只存在基本的行和列,对于基本表格展示,我们仅需关注需要展示多少行和列,行列的布局生成逻辑,以及这些行列如何通过数据进行映射。
前面的文章提到过, VTable 中是用 createGroupForFirstScreen 来创建整个场景树的,我们直接从这个函数里来解析。
createGroupForFirstScreen
// packages\vtable\src\scenegraph\group-creater\progress\create-group-for-first-screen.ts
createGroupForFirstScreen(
cornerHeaderGroup: Group,
colHeaderGroup: Group,
rowHeaderGroup: Group,
rightFrozenGroup: Group,
bottomFrozenGroup: Group,
bodyGroup: Group,
xOrigin: number,
yOrigin: number,
proxy: SceneProxy
) {
* // 阶段1:参数初始化*
proxy.setParamsForRow(); *// 计算行的更新位置,行更新的数量和新的范围*
proxy.setParamsForColumn(); *// 计算列的更新位置,列更新的数量和新的范围*
*// 阶段2:计算首屏渲染范围*
*// 列范围计算逻辑*
distCol = Math.min(proxy.firstScreenColLimit - 1, table.colCount - 1);
*// 行范围计算逻辑*
distRow = Math.min(proxy.firstScreenRowLimit - 1, table.rowCount - 1);
*// 阶段3:自适应计算(首次渲染需要精确计算)*
if (未手动调整列宽) {
computeColsWidth(table, 0, distCol); *// 计算列宽*
}
if (未手动调整行高) {
computeRowsHeight(table, 0, distRow); *// 计算行高*
}
*// 阶段4:定位容器组*
table.scenegraph.colHeaderGroup.setAttribute('x', table.getFrozenColsWidth());
table.scenegraph.bodyGroup.setAttributes({
x: table.getFrozenColsWidth(),
y: table.getFrozenRowsHeight()
});
*// 阶段5:填充列容器(核心)*
*// 5.1 填充角表头*
createColGroup(cornerHeaderGroup, ...);
*// 5.2 填充顶部表头*
createColGroup(colHeaderGroup, ...);
*// 5.3 填充左侧表头(含行号列)*
createColGroup(rowHeaderGroup, ...);
*// 5.4 填充 body group*
createColGroup( ... , bodyGroup, ... );
//... 填充剩下的容器
*// 阶段6:启动渐进渲染*
if (有数据) {
proxy.progress(); *// 启动异步渲染任务*
}
}
可以看到,在 createGroupForFirstScreen 一套流程下来后,完成了场景树的填充。内部不断调用 createColGroup 来实现容器的填充。
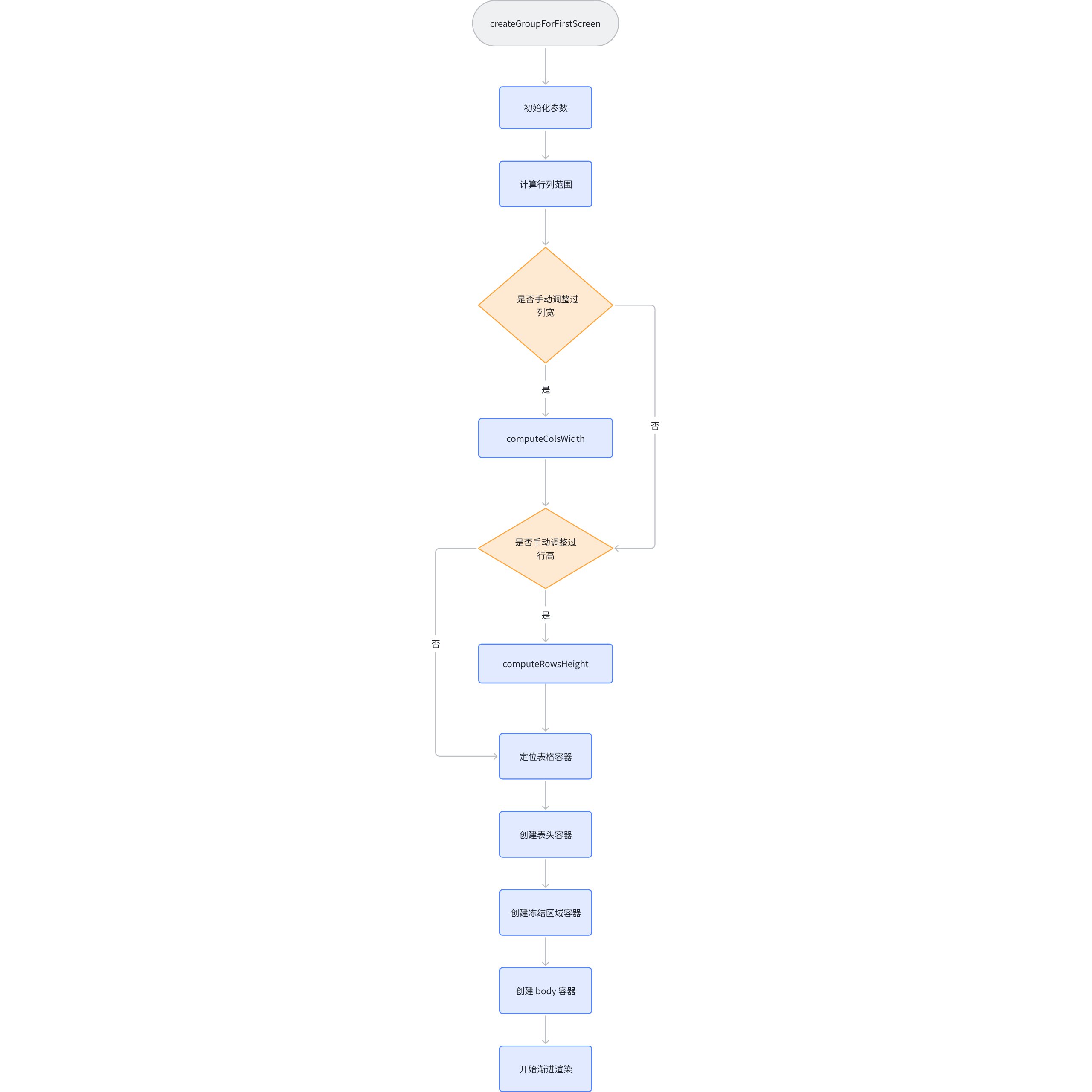
- packages\vtable\src\scenegraph\group-creater\column.ts
生成一个列的场景节点,按照开始和结束列去调用 createComplexColumn填充 ColumnGroup ,同时更新每列的高度
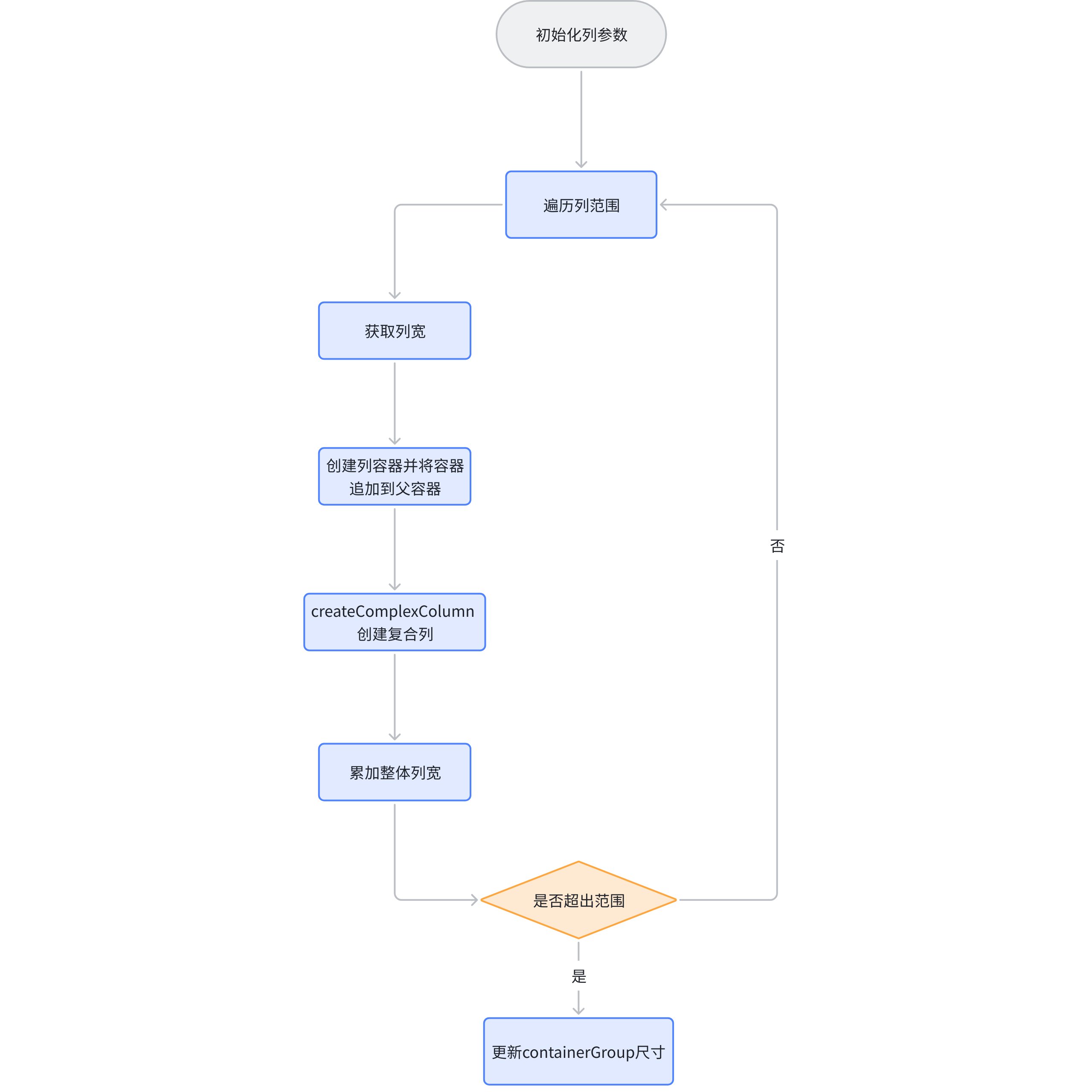
createComplexColumn
- packages\vtable\src\scenegraph\group-creater\column-helper.ts
根据行范围创建每一行的图元,会根据行分为去常见单元格 cellGroup
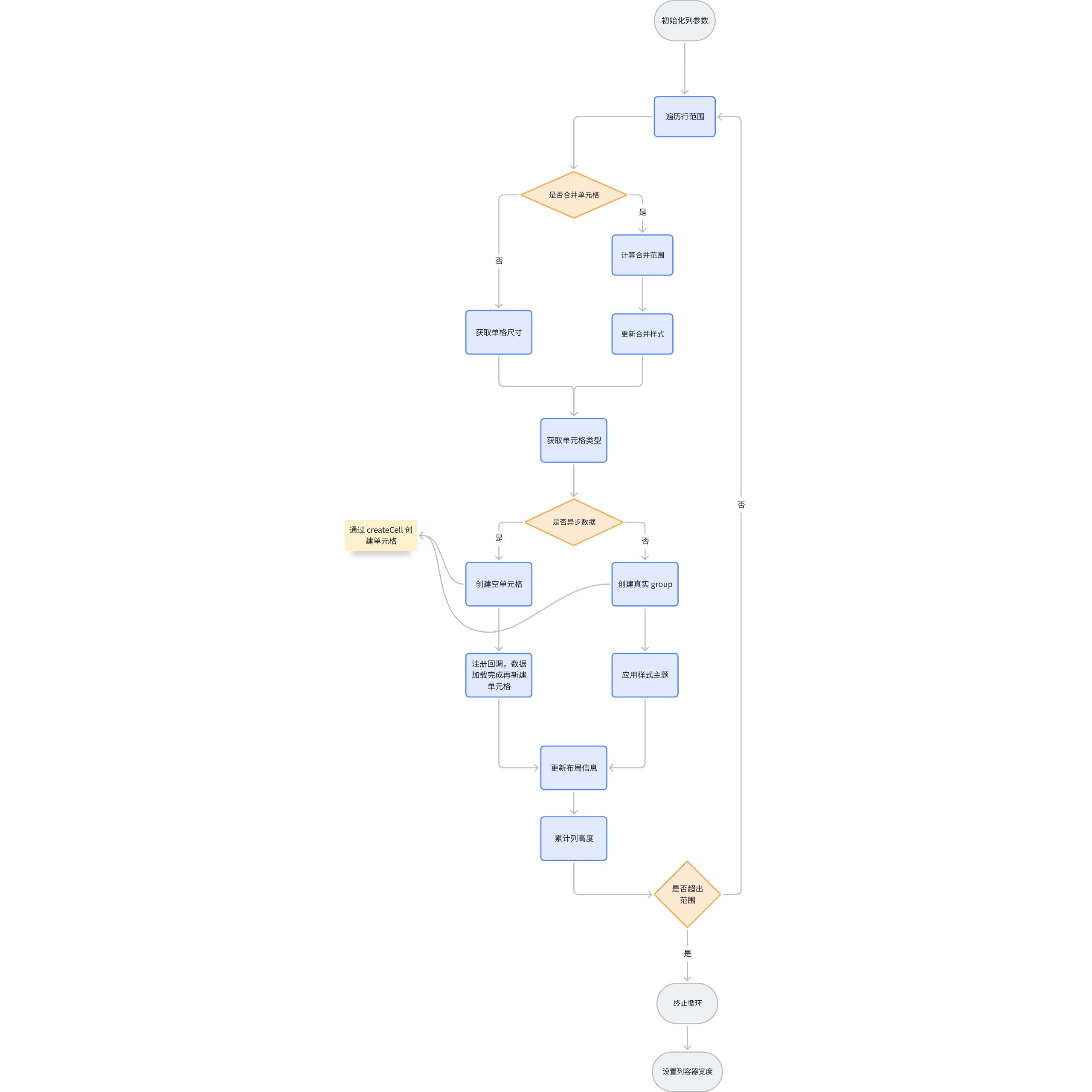
createCell
从内部的 import 可以发现 ,createCell 是单元格容器的创建收口。createCell 会去根据传入的配置创建单元格,并插入到对应的列容器中,根据不同的 type 生成不同的图元。
// packages\vtable\src\scenegraph\group-creater\cell-helper.ts import type { CreateChartCellGroup } from './cell-type/chart-cell'; import type { CreateImageCellGroup } from './cell-type/image-cell'; import type { CreateProgressBarCell } from './cell-type/progress-bar-cell'; import type { CreateSparkLineCellGroup } from './cell-type/spark-line-cell'; import type { CreateTextCellGroup } from './cell-type/text-cell'; import type { CreateVideoCellGroup } from './cell-type/video-cell';
基本表格布局组织全流程
从上面的逻辑来看,VTbale 的基本展示流程,先是创建了所有需要用的容器,包括表头容器和 body 容器,随后先按列遍历表头创建表头列容器,然后按照行配置每行创建单元格容器、再创建 body 列容器,继续按照行配置生成单元格容器。
简单来说就是先创建各个结构容器,再创建列容器,再就是单元格。
验证
我们在 createCell 中打印下 value,来看下创建的顺序是否和我们分析的相同
- packages\vtable\src\scenegraph\group-creater\cell-helper.ts
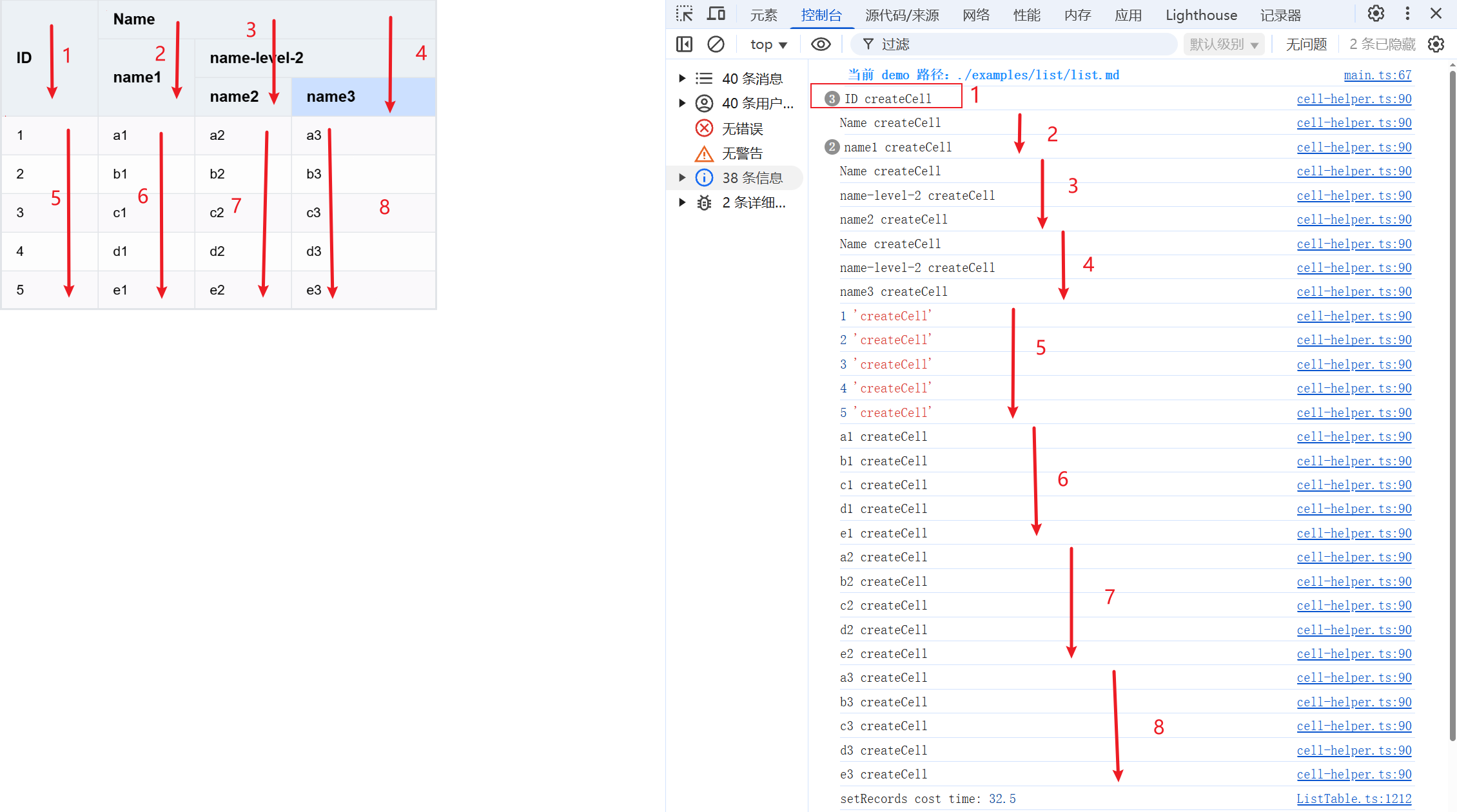
观察控制台的输出,完美验证了我们的之前的分析。
数据展示
获取单元格的值
聊完了基本表格的布局流程,现在来看下基本表格是如何获取每个单元格需要展示的 value吧。
回到上文提到的 createComplexColumn 里面,可以看到在创建单元格之前,都会去调用 table.getCellValue 去获取当前单元格的展示值。对于基本表格而言,table 代表的就是 ListTable。
// packages\vtable\src\scenegraph\group-creater\column-helper.ts
export function createComplexColumn() {
// 省略
let value = table.getCellValue(col, row);
// 省略
}
对于 body 部分的单元格,ListTable.getCellValue 的最底层会去用到 _currentPagerIndexedData ,这个值代表的是当前页每一行对应 records 的索引,会在 DataSource.updatePagerData方法中去根据 pagination 和 currentIndexedData 更新。
由于 _currentPagerIndexedData的存在, 在想要获取单元格值的时候,只需通过当前行的索引去原始数据中查出 record ,然后再根据列索引就可以匹配出单元格的原始值了。
而关于表头单元格值的获取,则是直接去取 _headerObjectMap 中对应的配置,变相获取 columns 中对应的 title,再将其做一些特殊的处理,再去做为表头单元格的值,具体过程在此处就不做赘述。
currentIndexedData
关于 currentIndexedData ,在中已经提到过了。这里再重点讲下其含义与用法。
由于 ListTable 存在多种交互方式,行列转置,树形结构等,在获取单元格值时的难度非常大。为此 ,ListTable 中引入了 currentIndexedData(每一行对应源数据的索引) 来对数据进行辅助处理。
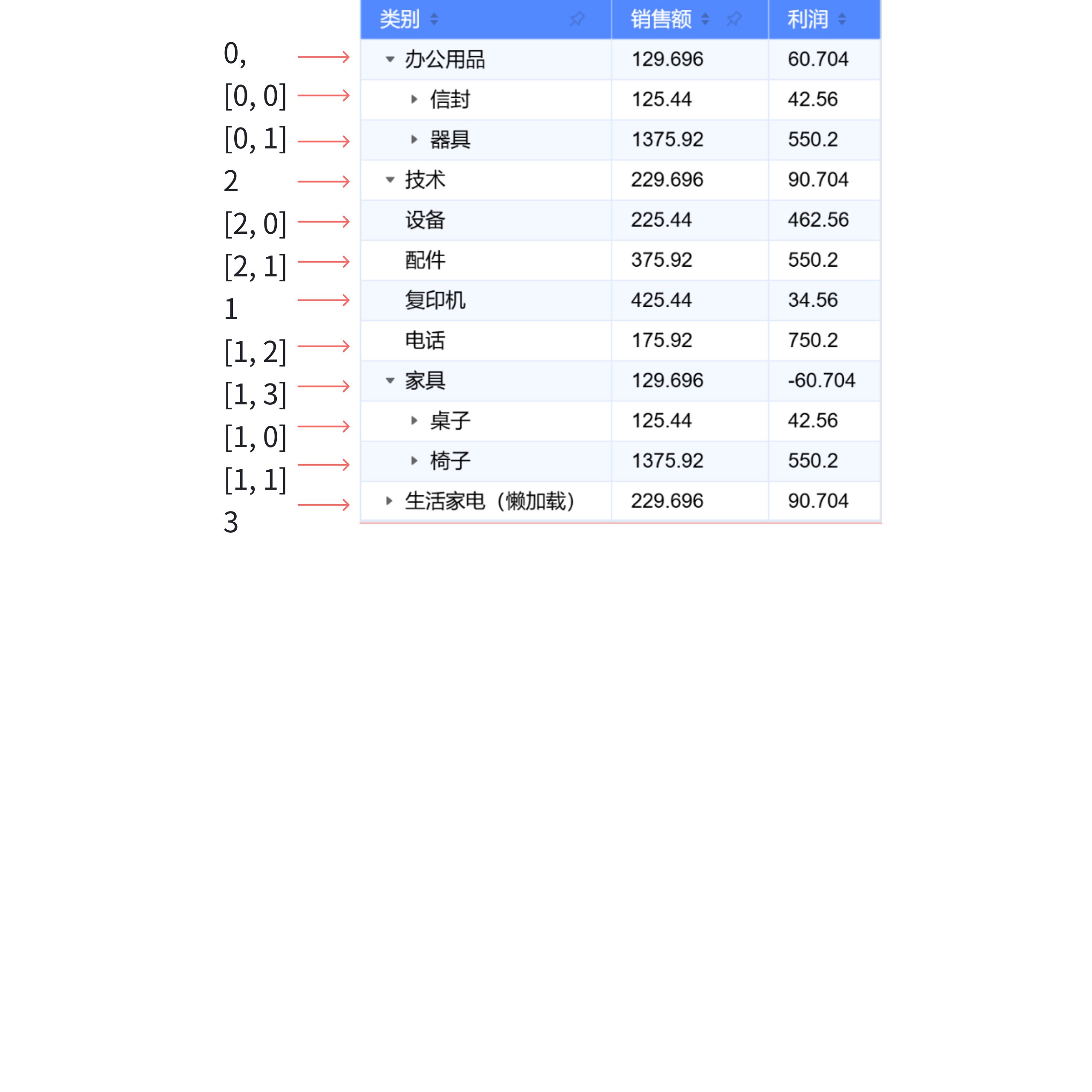
我们以一个树形结构来举例
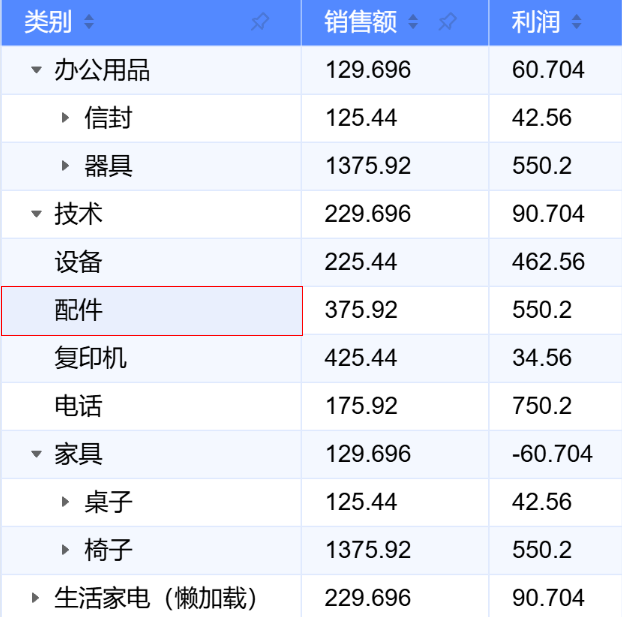
他的 currentIndexedData 长这样。
[ 0, // 数据源对应第1条数据 紧邻其下的是第1条数据的子节点 说明第1条数据被展开了 [0, 0], // 数据源对应第1条下的 第1个子节点 [0, 1], // 数据源对应第1条下的 第2个子节点 1, // 数据源对应第2条数据 [1, 0], // 以此类推 。。。 [1, 1], [1, 2], [1, 3], 2, [2, 0], [2, 1], 3 ];
那该如何去使用 currentIndexedData 呢,可以参考 DataSource.getValueFromDeepArray 方法。举个例子,获取第二行的数据,读取方式就是 tableInstance.dataSource.records[0].children[0],正好对应了 [0,0]。
通过将直接读取或修改原始数据的方式抽象成通过索引去调整和获取对应行 record 的形式、不需要去修改原数据,可以使得在对布局进行更新时,仅需关注每行对应的索引,无需再关心原始数据,降低心智负担。
行列转置
概念
行列转置是将表格的行和列进行调换,该功能只在基本表格中有。
不同于其它基于原生 DOM 的表格组件库需要进行复杂的自定义才能完成转置的功能,ListTable 仅需一个配置就可以开启行列转置。现在来看下 ListTable 是如何实现这个功能的吧。
场景树创建流程
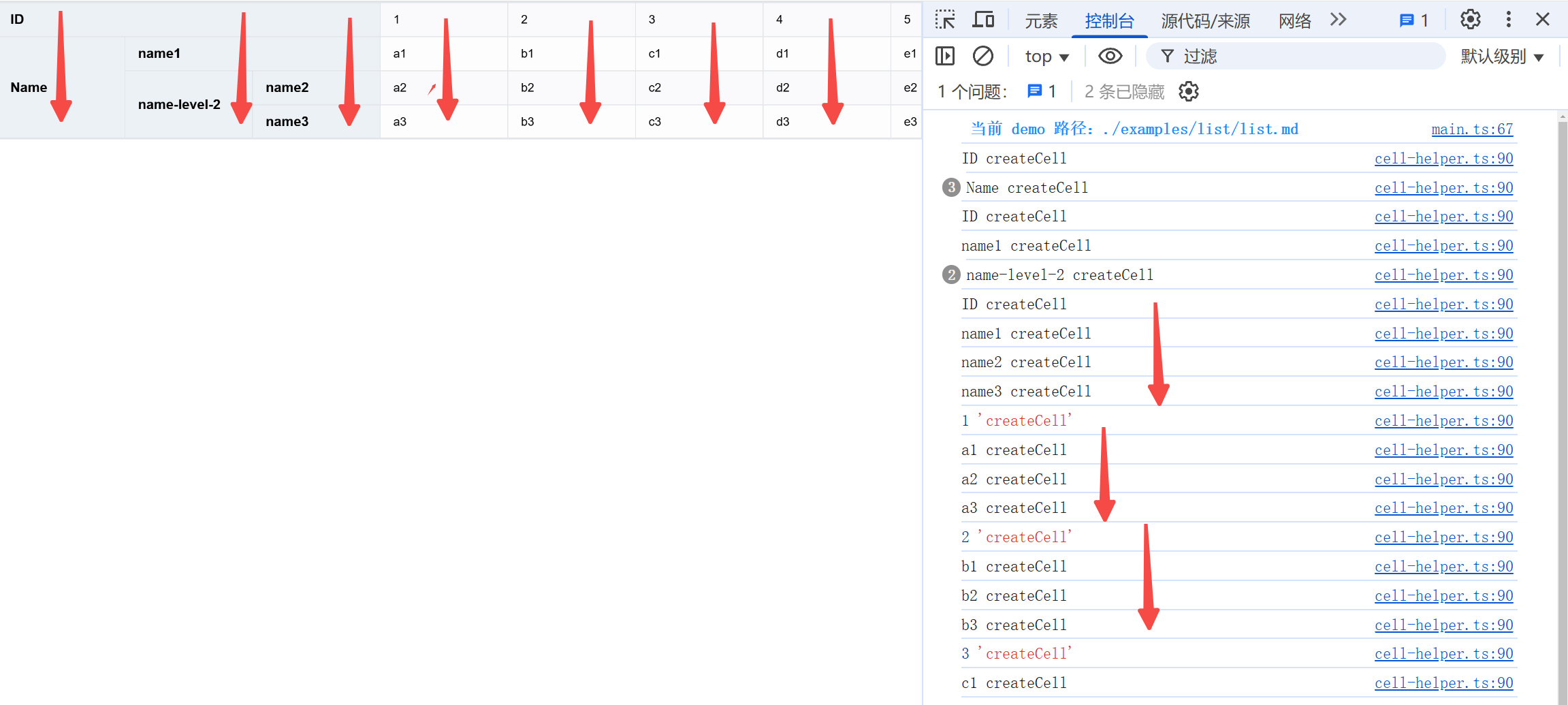
通过观察 getCellValue 的调用,发现场景树的创建流程还是相同的。
转置后的处理
思考一下,如何去处理转置后的数据,可以明显的想到两种方法:
-
直接变更 records
-
在读取数据的时候去根据是否转置来特殊处理
ListTable 在内部采用的第二种方案。为何不采用第一种方案,是因为内部对 records 存在了太多的依赖, 包括数据增删改查,如果直接对 records 进行改动影响的面非常多,更不用说用户需要频繁修改数据的情况,需要兼容的地方非常多。
我们用线性代数中的转置矩阵来做下比较,转置矩阵就是把行数变成列数,列数变成行数。原来通过 records[row][col] 来取值,现在要通过 records[col][row] 来取值。
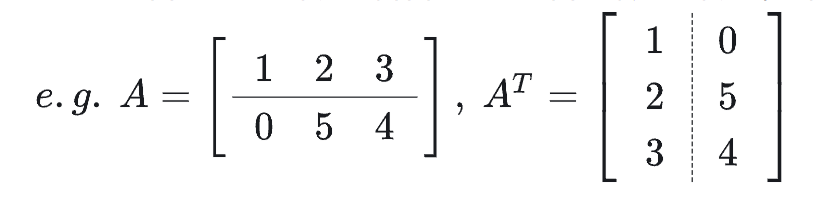
原来通过 row 来判断是不是表头,现在需要通过 col 来进行判断。
// packages\vtable\src\layout\simple-header-layout.ts isHeader(col: number, row: number): boolean { if ( this.transpose && col >= this.leftRowSeriesNumberColumnCount && col < this.headerLevelCount + this.leftRowSeriesNumberColumnCount ) { return true; } if (!this.transpose && row >= 0 && row < this.headerLevelCount) { return true; } return false; }
从 ListTable 内部关于 transpose 的特殊处理部分来看,转置不仅影响了表头和 body 部分的判断逻辑,还影响了行数和列数的转换、取数时 col 和 row 的调整、表格宽度和高度的计算等多处地方。
树形结构
使用背景
当用户有查看具有层次结构的数据需求时,就会用到树形结构。
下面是 ListTable 树形结构的一个例子:
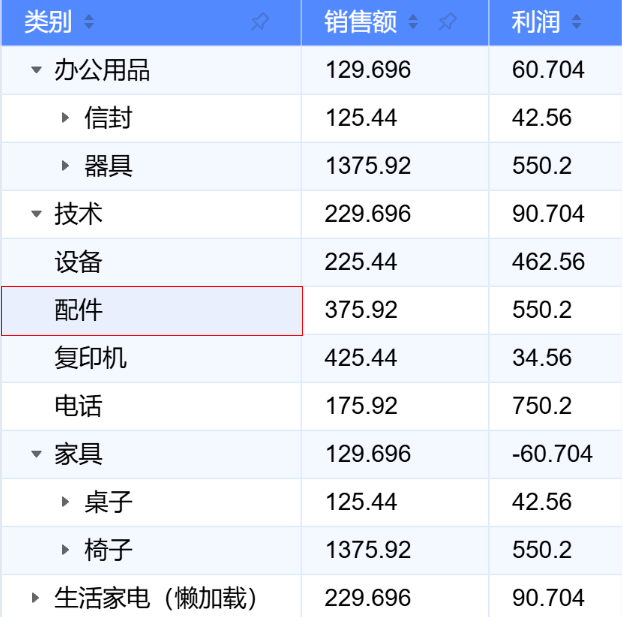
配置
ListTable 中采用的是市面上常用的数据配置,通过数据嵌套 children 、同时在 columns 中指定 tree 属性来实现树形结构。
树形表格处理
流程分析
-
解析 option:
-
在 layoutMap 初始化的时候会根据 column 配置是否包含 tree 字段或�者 groupBy 配置来动态调整 rowHierarchyType 。后续会根据 rowHierarchyType 做特殊判断。
// packages\vtable\src\layout\simple-header-layout.ts
export class SimpleHeaderLayoutMap implements LayoutMapAPI {
constructor() {
// 省略
this.rowHierarchyType = checkHasTreeDefine(this) ? 'tree' : 'grid';
}
}
-
rowHierarchyType为 true 时,会去调用 initTreeHierarchyState,初始化默认的单元格展开状态,调整 **hierarchyState (单元格树形结构的展开/收起状态) **和 **hierarchyExpandLevel **(树形结构展开的层数)
-
处理布局:收起展开按钮占位布局计算,以及根据用户配置的子节点缩进距离 hierarchyIndent 来定位内容展示位置;
-
处理数据:需要对树形结构的数据进行特殊处理,包括增删改查、排序等逻辑;
以排序为例,ListTable 内部针对树形结构做了下面几步:
-
获取待排序的列,ListTable 支持多列排序;
-
如果存在上一次排序后缓存的数据,则直接使用(缓存优化,这个缓存会在数据更新时清除)
-
遍历第一步得出来的所有待排序列,对树形结构第一层进行排序,调整 currentIndexedData;ListTable 排��序的标准是以先点击的列为准;
-
从上往下遍历,依次调用 pushChildrenNode,对子节点进行排序,再将排序后的数据插入到父节点下;
-
递归调用 pushChildrenNode,持续对子节点进行排序;
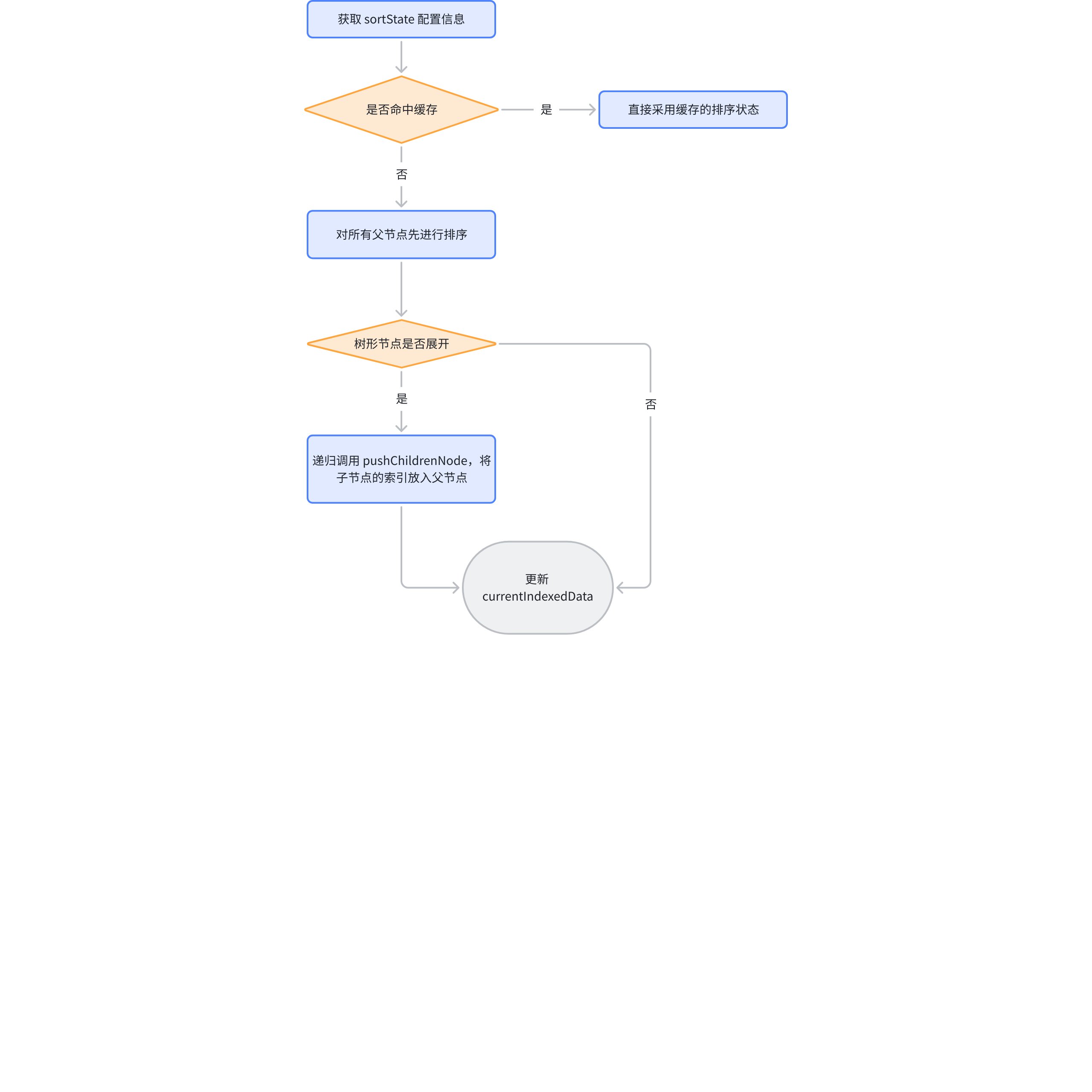
这里是点击类别进行升序后的 currentIndexedDatra,可以明显看到相应的变换,家具 排在了 技术 的前面:
-
事件绑定:通过绑定 ICON_CLICK 事件,在点击展开收起图标时,调用 table.toggleHierarchyState 调整表格,同时维护 currentIndexedData ,并通过回调将相应的事件和参数上报给用户。
-
表格渲染:根据表格列定义进行布局
-
渲染节点时进行展开收起的判断,针对不同情况调整节点的图标;通过展开收起状态(hierarchyState)来判断节点的图标。注意的是,根节点的 hierarchyState 为 NONE ,所以不存在图标;
-
根据层级调整单元格的缩进值以及列宽的计算方式;
-
异步加载:面对有大数据量的需求的时候,将 children 设置为 true,可以开启异步渲染。监听树形结构的展开收起事件,手动调用 setRecordChildren 来插入数据。
缩进的计算方式
关于树形结构的缩进,影响了两个部分,一个是单元格内部缩进的计算逻辑,另一个是单元格自动宽度的计算。
- 计算列宽
在计算列宽的核心逻辑中,有一段代码是专门针对缩进进行处理的。
计算公式用伪代码表示:cellHierarchyIndent = 当前的缩进层级 * hierarchyIndent + 展开收起图标的宽度
后续在计算列宽时会去在原有单元格长度上,再加上这个 cellHierarchyIndent。
// packages\vtable\src\scenegraph\layout\compute-col-width.ts
function computeAutoColWidth(...): number {
// 省略
*// 基本表格表身body单元格 如果是树形展开 需要考虑缩进值*
const define = table.getBodyColumnDefine(col, row);
if ((define as ColumnDefine)?.tree) {
const indexArr = table.dataSource.getIndexKey(table.getRecordShowIndexByCell(col, row));
cellHierarchyIndent =
Array.isArray(indexArr) && table.getHierarchyState(col, row) !== HierarchyState.none
? (indexArr.length - 1) * ((layoutMap as SimpleHeaderLayoutMap).hierarchyIndent ?? 0)
: 0;
// 省略
}
// 省略
}
- 单元格内部缩进计算
在文本单元格创建的过程(createTextCellGroup)中,内部有调用到这么一个方法getHierarchyOffset。
里面涉及到了缩进偏移值的计算(cellHierarchyIndent),计算公式为cellHierarchyIndent = 当前的缩进层级 * hierarchyIndent + 展开收起图标的宽度,通过这个公式可以得出缩进的偏移量,从而在单元格生成时进行文本定位,调整 x 方向的偏移值。
状态切换
前面提到了基本表格内部通过 currentIndexedData 来管理数据,我们先通过 currentIndexedData 来看下节点展开时发生了什么变化:
- 点击
信封前
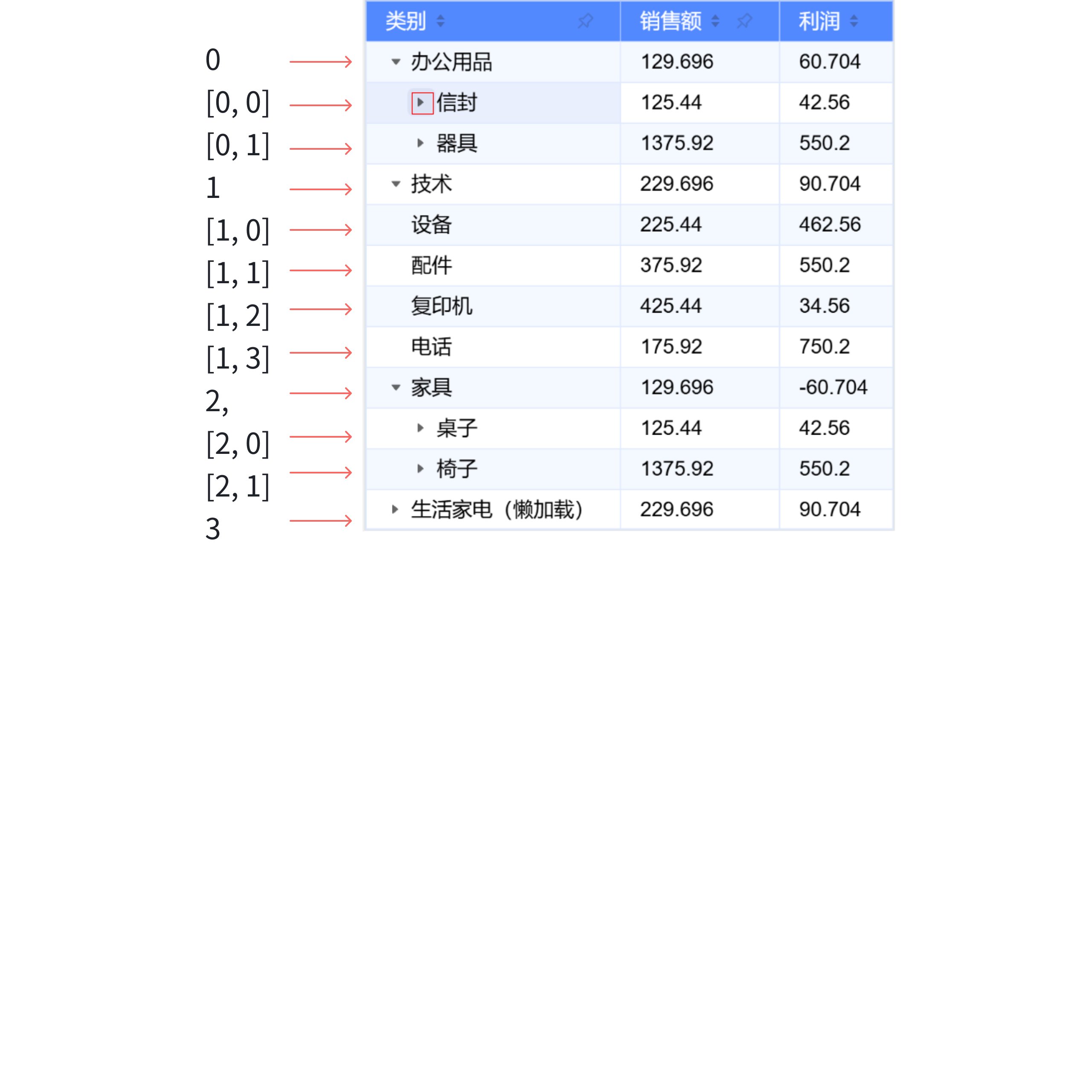
- 点击
信封后
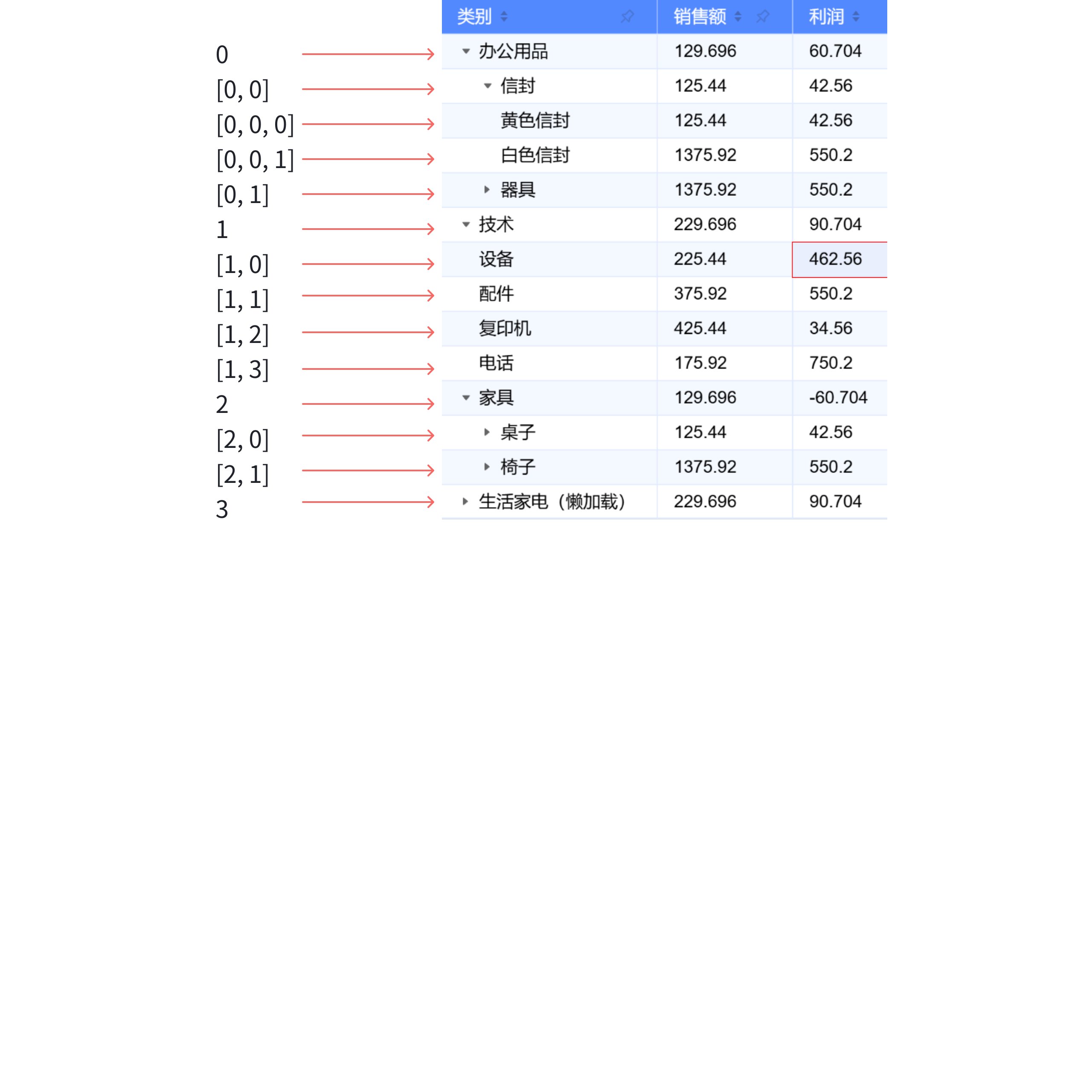
很明显的看到,在 信封 下面插入了两行数据,分别是 [0,0,0] 和 [0,0,1];代表的就是 黄色信封 和 白色信封
- 再观察点击
信封的展开时,getCellValue 的输出:

可以看到的是,先是对 信封 以下的所有单元格都进行了更新,随后创建了信封children 的其它列容器。
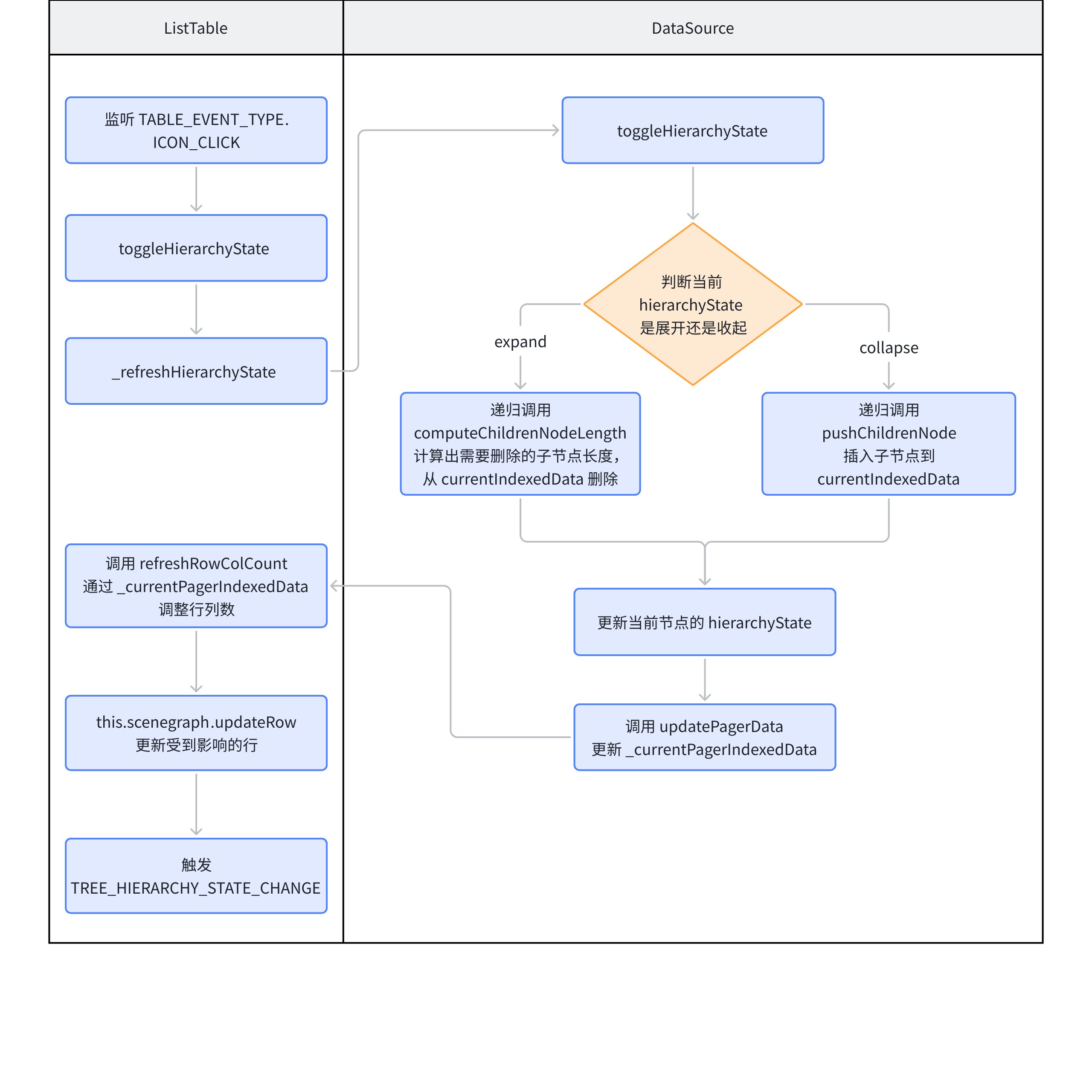
那么对于节点的展开切换,可以抽象为下面几步:
-
父节点的图标切换:通过调整 nodeData 的 hierarchyState 来调整展开/收起图标;
-
子节点的插入与删除:
-
展开时递归调用
pushChildrenNode插入子节点,更新 currentIndexedData; -
删除时递归调用
computeChildrenNodeLength计算出受到影响的行数,直接操作删除 currentIndexedData; -
数据更新:通过 currentIndexedData 更新 _currentPagerIndexedData;
-
更新行列数:通过 _currentPagerIndexedData 调整行列数;
-
更新场景树:调用
scenegraph.updateRow更新场景树; -
触发业务方传进来的回调
TREE_HIERARCHY_STATE_CHANGE;
分组
场景分析
基本表格分组展示功能适用于多种场景,例如:
-
财务报表:可以按照不同的账户类型(如收入、支出、资产、负债)进行分组展示,帮助更清晰地了解财务状况。
-
销售数据分析:可以按照产品类别、地区、销售人员等进行分组,方便比较和分析不同类别或区域的销售表现。
案例
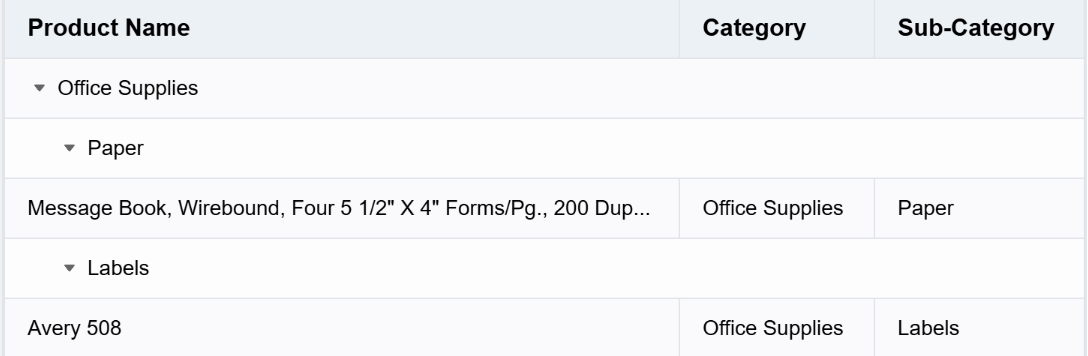
const data = [ { Category: 'Office Supplies', 'Sub-Category': 'Paper', 'Product Name': 'Message Book, Wirebound, Four 5 1/2" X 4" Forms/Pg., 200 Dupl. Sets/Book' }, { Category: 'Office Supplies', 'Sub-Category': 'Labels', 'Product Name': 'Avery 508' } ]; const option = { records: data, columns, widthMode: 'standard', groupBy: ['Category', 'Sub-Category'], enableTreeStickCell: true };
关于树形结构的展开收起在前面已经讲过了,在分组章节中我们来重点看下关于数据的处理部分。
内部数据处理
我们来观察下上面这个例子中的 currentIndexedData,能够明显的发现其有五行,但是在初始化时 records 中只传入了两行,那么很容易就可以发现,ListTable 内部帮我们插入了三行,这三行代表的就是 ListTable 内部生成的分组表头。

currentIndexedData 发生了变化,代表了 records 肯定有调整,再来观察下 tableInstance.dataSource.records,很明显,和原始传入的 records 大相径庭。
说明 ListTable 将原有的二维数组结构转为了树形结构,并自动做好了分组。
[ { "vtableMerge": true, "vtableMergeName": "Office Supplies", "children": [ { "vtableMerge": true, "vtableMergeName": "Paper", "children": [ { "Category": "Office Supplies", "Sub-Category": "Paper", "Product Name": "Message Book, Wirebound, Four 5 1/2\" X 4\" Forms/Pg., 200 Dupl. Sets/Book" } ], "hierarchyState": "expand" }, { "vtableMerge": true, "vtableMergeName": "Labels", "children": [ { "Category": "Office Supplies", "Sub-Category": "Labels", "Product Name": "Avery 508" } ], "hierarchyState": "expand" } ], "hierarchyState": "expand" } ]
注意观察在树形结构中有几个特殊的字段,分别是:
-
hierarchyState:在前面提到过,这个字段表示的是当前节点的展开收起状态;
-
vtableMerge:表示是否是合并单元格,对于合并单元格,ListTable 会有特殊的处理;
-
vtableMergeName:合并单元格的名称;
通过上面的分析,我们能够了解到 ListTable 内部对于分组大致做了什么。
那么 ListTable 是如何对二维数据进行分组形成树形结构的呢,这就涉及到 ListTable 内部的分组算法了。
核心分组算法
ListTable 内部分组算法的��核心是 dealWithGroup
参数解析
该方法接收五个参数
// packages\vtable\src\data\CachedDataSource.ts
function dealWithGroup(record, children, map, groupByKeys, level) { ... }
-
record - 当前处理的数据记录;
-
children - 当前层级的子节点数组,在遍历处理所有 records 前,会先生成最外层的一个 groupResult,将其做为 children,后续就是通过 递归 插入子元素;
-
map - 当前分组节点
下一级的分组值和在分组节点 children 内部对应索引的映射表;在每层分组节点中都会单独维护一份,后续再遇到相同的分组值时,会直接插入到相同的索引处; -
groupByKeys - 分组字段数组,option 中传入的 groupBy;
-
level - 当前处理的分组层级
分组节点
这是一个分组节点的通用结构
{
vtableMerge: true,
vtableMergeName: value,
children: [] as any,
map: new Map()
}
其中:
- vtableMergeName:当前 record 对应的分组值,比如这么一条数据
{
Category: 'Office Supplies',
'Sub-Category': 'Paper',
'Product Name': 'Message Book, Wirebound, Four 5 1/2" X 4" Forms/Pg., 200 Dupl. Sets/Book'
}
假如当前层级对应的 groupKey 为 Category,那对于这一层的分组节点来说,vtableMergeName 为 Office Supplies
-
vtableMerge:由于分组的缘故,对于分组标题,都是默认为整条都需要合并;
-
children:当前分组下对应的children ,由于可能有多个分组,所以是一个树形结构;
-
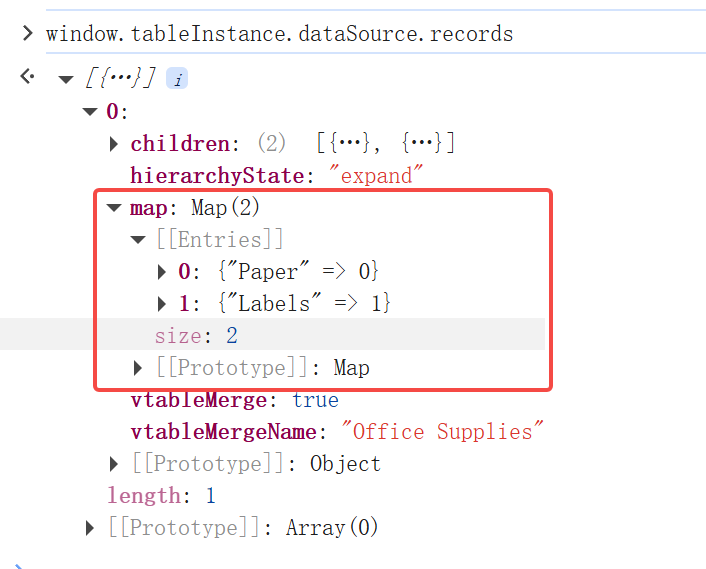
map:当前分组节点下的 children 中 分组值和在当前分组节点 children 中对应索引 的映射表,确保下次遇到相同的子分组时,能够快速插入到正确位置。
以上面例子中的分组举例,最外层的 Map 长这样。这就表示,如果后续再遇到 Office Supplies -> Paper 分组中的数据,便可以直接插入到 children[0] 中。
前置流程
// packages\vtable\src\data\CachedDataSource.ts
// 省略
const groupMap = new Map();
const groupResult = [] as any[];
for (let i = 0; i < records.length; i++) {
dealWithGroup(records[i], groupResult, groupMap, groupByKeys, 0);
}
return groupResult;
// 省略
在对 records 进行遍历前,会先生成最外层的一份 groupMap 和 groupResult,groupResult 做为树形结构的第一层,由于地址引用的原因,后续所有的 record 的插入都会插入到 groupResult 中;对每条数据遍历 dealWithGroup 完成后,将 groupResult 作为最终的 records 返回。
dealWithGroup 递归流程
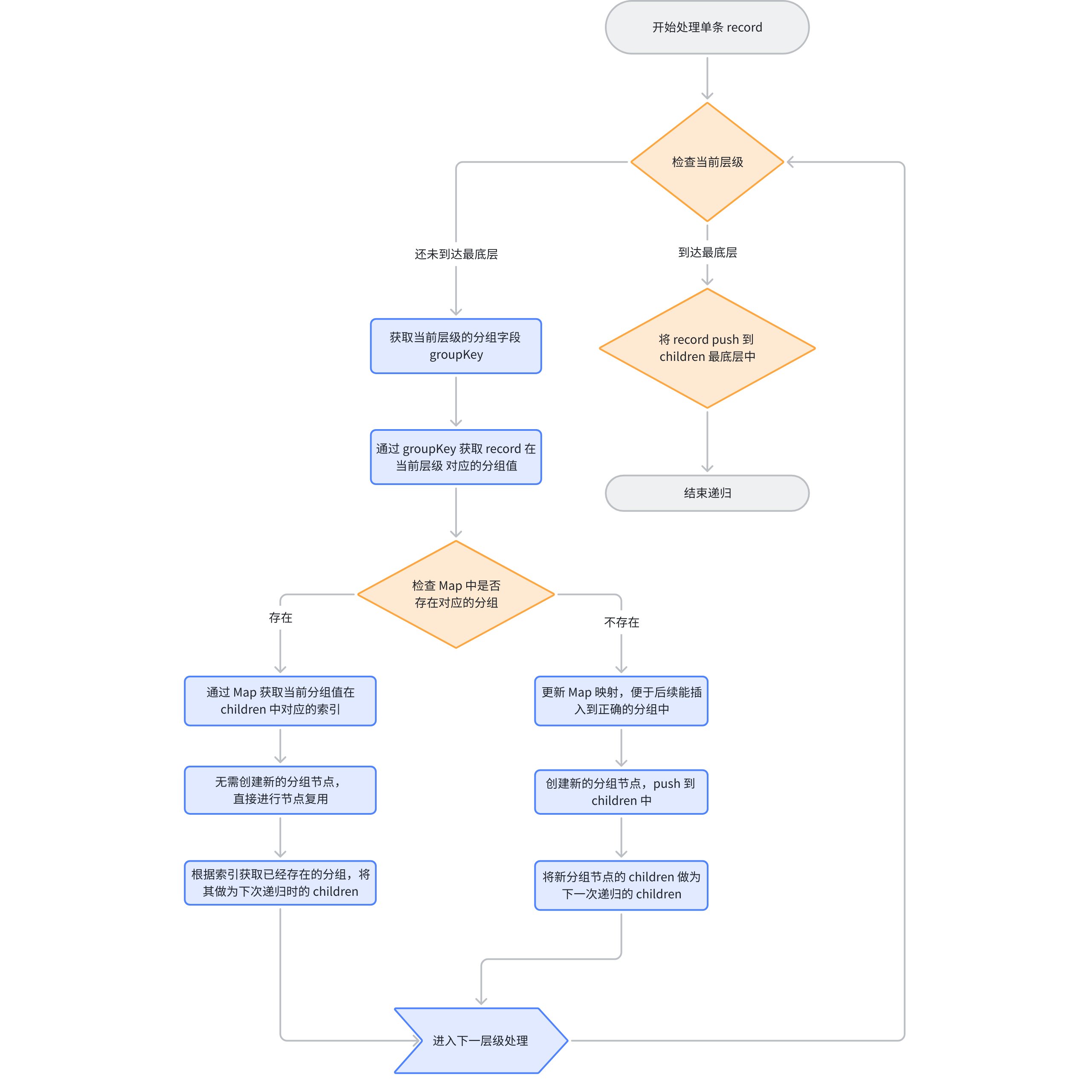
- 先是获取当前的 groupKey,判断是否到达最后一层,如果是最后一层直接塞到 children 中,代表递归完成:
// packages\vtable\src\data\CachedDataSource.ts if (!isValid(groupByKey)) { children.push(record); return; } // ...
- 通过 groupByKey 获取 value,判断当前 record 在这个层级下是属于哪一个分组;
// packages\vtable\src\data\CachedDataSource.ts const value = get(record, groupByKey);
- 通过 map 判断当前 value (分组值) 在
上一层分组节点中的children(即当前闭包中传入的 children)中是否存在,如果存在的话,说明是这个分组已经出现过了,直接复用相同的节点,并将其作为 children 传递到下一次递归逻辑;
// packages\vtable\src\data\CachedDataSource.ts
if (map.has(value)) {
const index = map.get(value);
return dealWithGroup(record, children[index].children, children[index].map, groupByKeys, level + 1);
}
- 如果 map 中不存在,则代表没有对应的分组节点,需要重新创建分组节点,并且更新上一层分组节点的 Map ,然后将新的节点塞到
上一层分组节点的children(即当前闭包中传入的 children) 的末尾,并且以这个新创建的节点作为下一次递归的children 参数,因为当前的 record 已经被判断为属于该分组了。同时返回递归处理后的结果。
// packages\vtable\src\data\CachedDataSource.ts
map.set(value, children.length);
children.push({
vtableMerge: true,
vtableMergeName: value,
children: [] as any,
map: new Map()
});
return dealWithGroup(
record,
children[children.length - 1].children,
children[children.length - 1].map,
groupByKeys,
level + 1
);
至此针对单条 record 的 dealWithGroup 就已经处理完了,下面是对应的流程图:
案例分析
我们以上面的 records 为例,在完成第一条 record 的处理后,来看下 groupResult 和 groupMap 是什么状态:
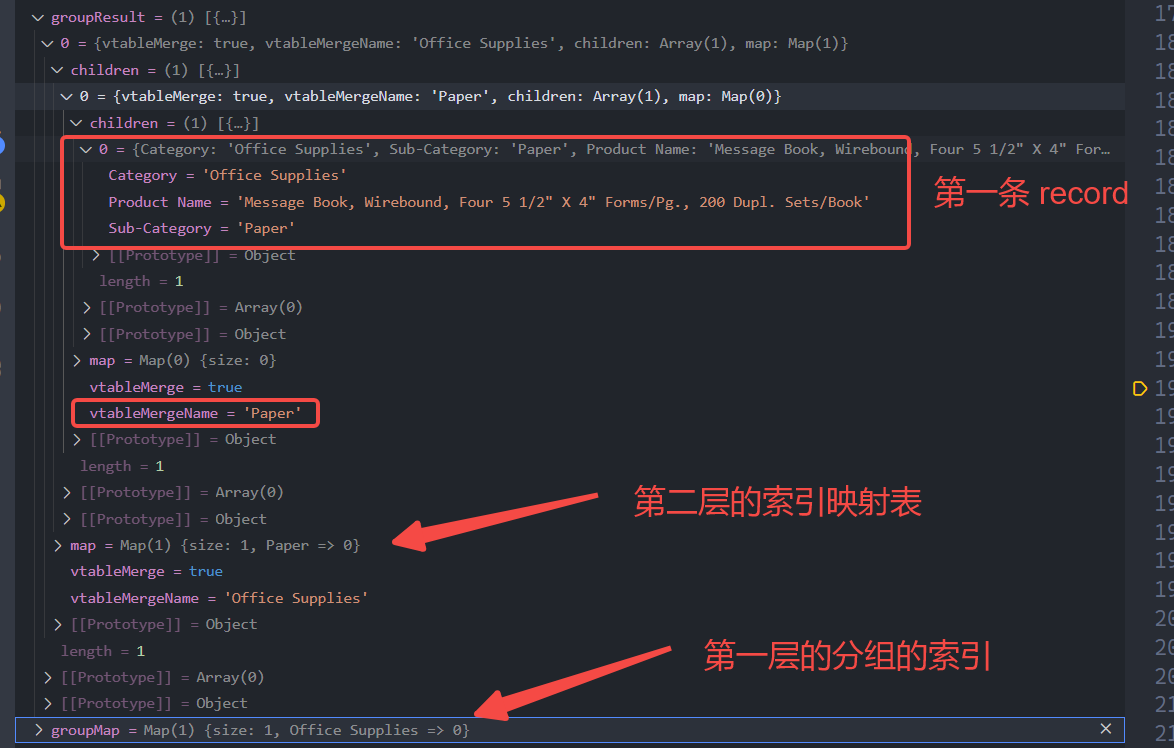
可以看到第一条 record 已经被正确的进行分组了,同时塞入到 groupResult[0].children[0] 中,并且在 groupMap 中已经存下了 Office Supplies 分组对应的索引。
那么在插入第二条 record 时就不会在第一层创建新的分组节点,而到第二层 Sub Category 层级时 ,由于 children[0].map 中没有 Labels 节点的记录,就会创建新的 Paper 节点,同时将 record 放到对应该节点的 children 中。
如果还有更多的数据,都会按照这个规律去走。在对所有 records 完成处理后,会将最终形成的 groupResult 赋值给tableInstance.dataSource.records ,完成分组的数据处理。
由于每个节点单独维护了 Map,在递归的过程中会极大程度降低时间复杂度。
经典交互
前面提到过,VTable 的底层是基于 VRender 的,大部分的交互都是基于监听 VRender 提供的事件来实现的,现在从几个经典的交互来入手,看看 ListTable 是如何通过监听 VRender 提供的事件来实现媲美原生 DOM 的交互的。
拖拽调整列宽
常规的调整列宽方式主要是监听三个事件:
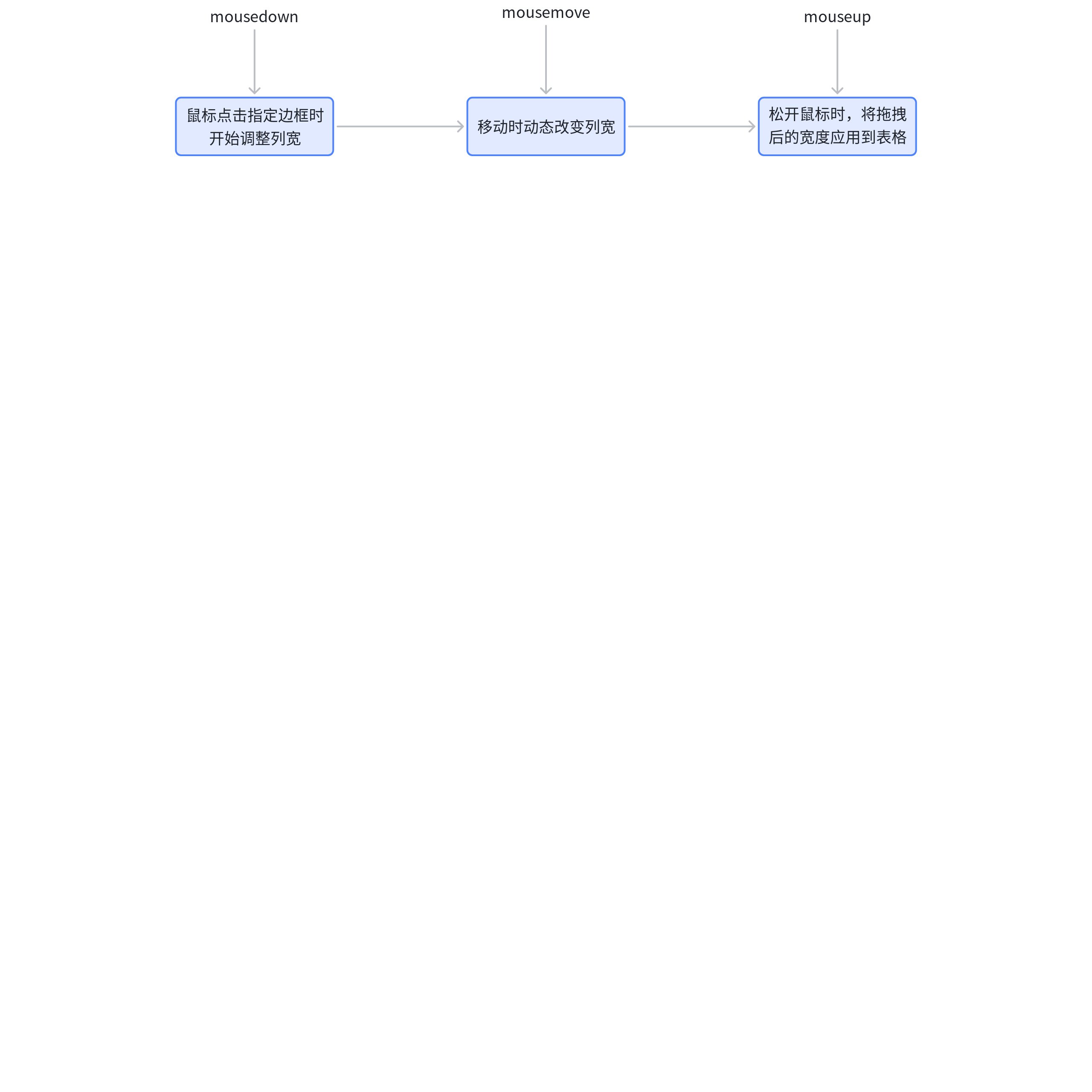
但是在 VTable 中,调整列宽主要是依赖于 pointer 事件:
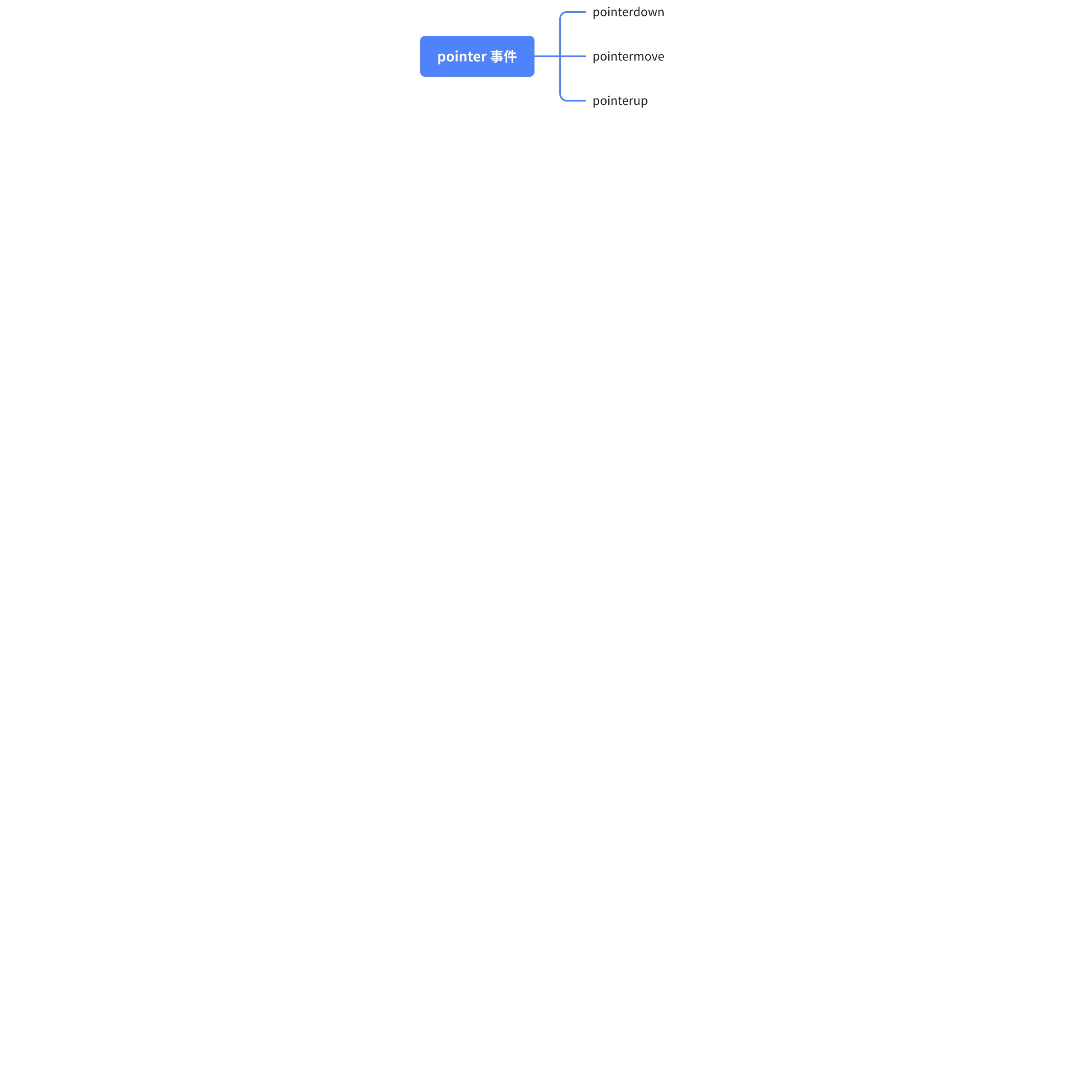
使用 pointer 事件主要是因为 pointer 不仅支持鼠标事件,同时还支持触控笔、触摸屏等所有指针设备,具有更好的兼容性。
开始拖拽调整列宽
拖拽列宽的开启主要是监听了 tableGroup 的pointerdown 事件,整体大概是下面这么一个流��程:

拖拽热区判断
你可能会好奇,ListTable 内部是如何去判断当前点击的是边框还是单元格?下面来看下 ListTable 是如何去进行判断的。
判断点击的地方是否在拖拽热区中,主要是依赖于 scenegraph.getResizeColAt,其中有段核心的代码
// packages\vtable\src\scenegraph\scenegraph.ts if (abstractX < cellGroup.globalAABBBounds.x1 + offset) { // 命中 左边界 cell = { col: cellGroup.col - 1, row: cellGroup.row, x: cellGroup.globalAABBBounds.x1 }; } else if (cellGroup.globalAABBBounds.x2 - offset < abstractX) { // 命中 右边界 cell = { col: cellGroup.col, row: cellGroup.row, x: cellGroup.globalAABBBounds.x2 }; }
-
globalAABBBounds:当前单元格的边界信息,x1 为左边界、x2 为右边界
-
abstractX:当前点击的位置信息 X 坐标
-
offset:拖拽热区宽度( resizeHotSpotSize )
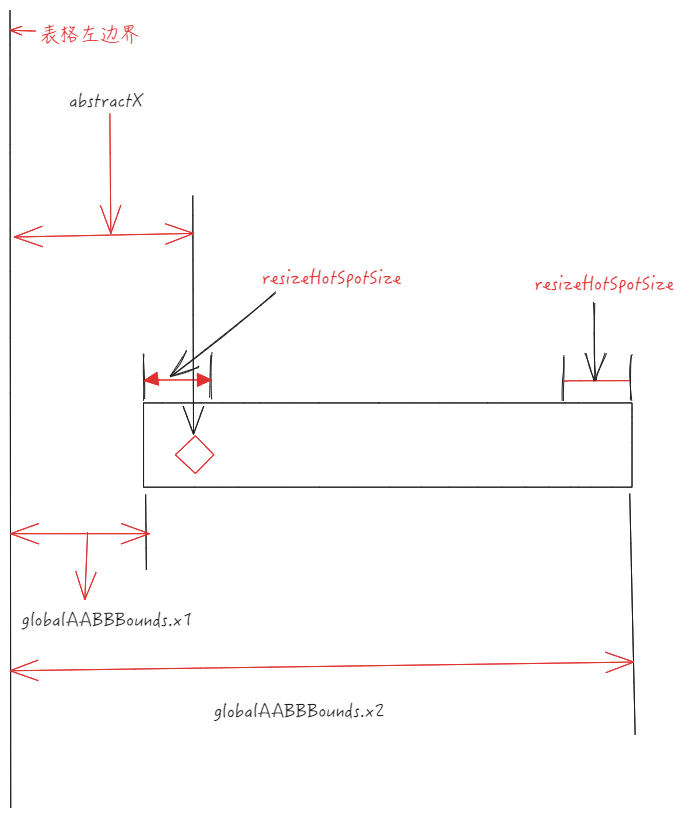
我们以左边界来举例:
当前点击的 X坐标 < 单元格左边界的 X 坐标 + resizeHotSpotSize 即代表命中左边的拖拽热区,这时就需要更新当前拖拽单元格的信息为左边的单元格,右侧拖拽热区同理。
下面是 getResizeColAt 整体的流程图
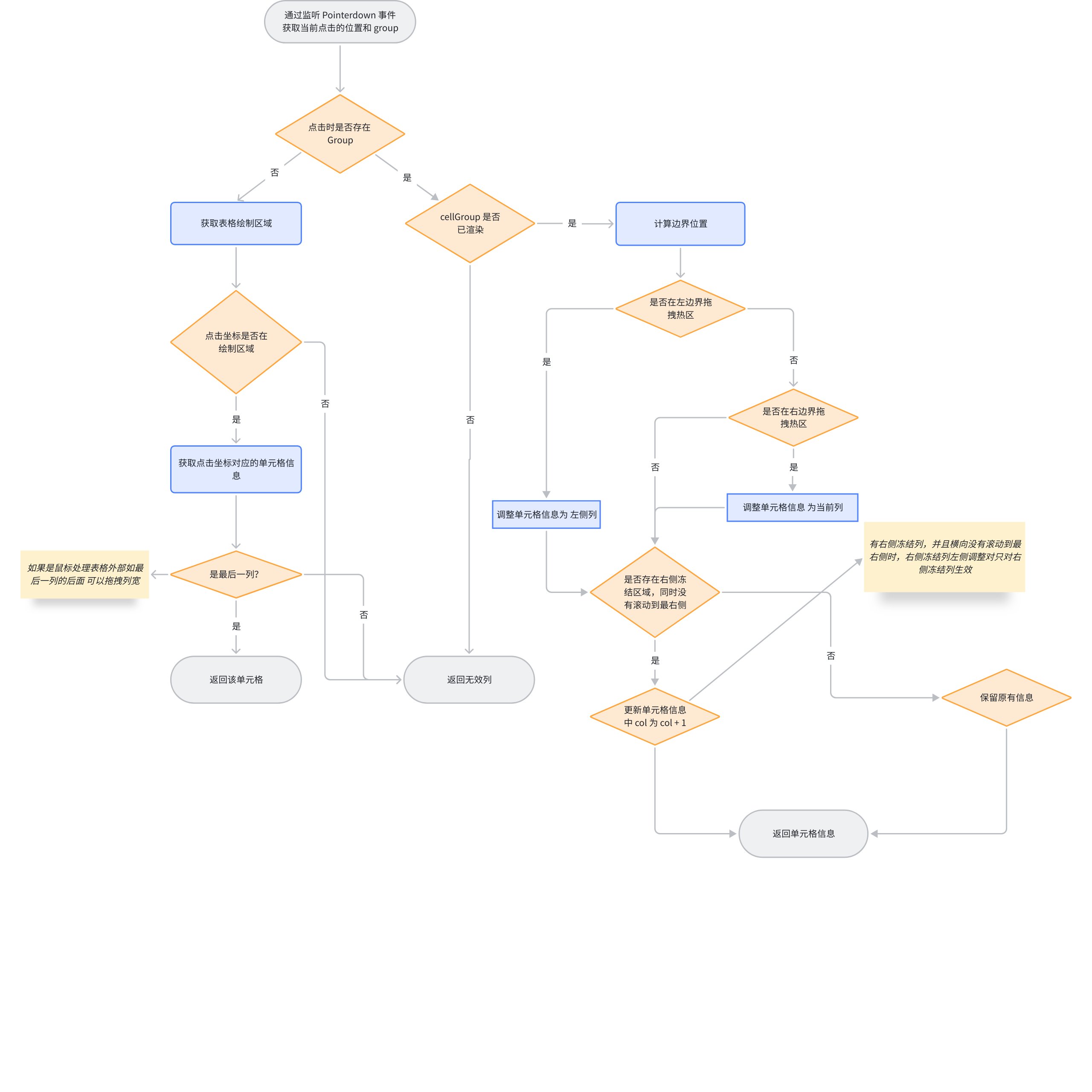
假如能够通过 getResizeColAt 获取点击的单元格信息,就代表命中了某一列的边界,才能够继续拖拽列宽动作。
startResizeCol 的影响
上一步中的 startResizeCol 会去更新 StateManager 中的 columnResize 状态,后面 pointermove 事件中就能通过 resizing 来判断到是否在拖拽列宽。
同时会记录开始拖拽时的 x 坐标和 列索引。
// packages\vtable\src\state\state.ts
startResizeCol(col: number, x: number, y: number, isRightFrozen?: boolean) {
this.columnResize.resizing = true;
this.columnResize.col = col;
this.columnResize.x = x;
this.columnResize.isRightFrozen = isRightFrozen;
this.table.scenegraph.component.showResizeCol(col, y, isRightFrozen);
}
拖拽ing
处理拖拽过程,主要是依赖于 pointermove 事件。下面是进入绑定相关拖拽事件的逻辑
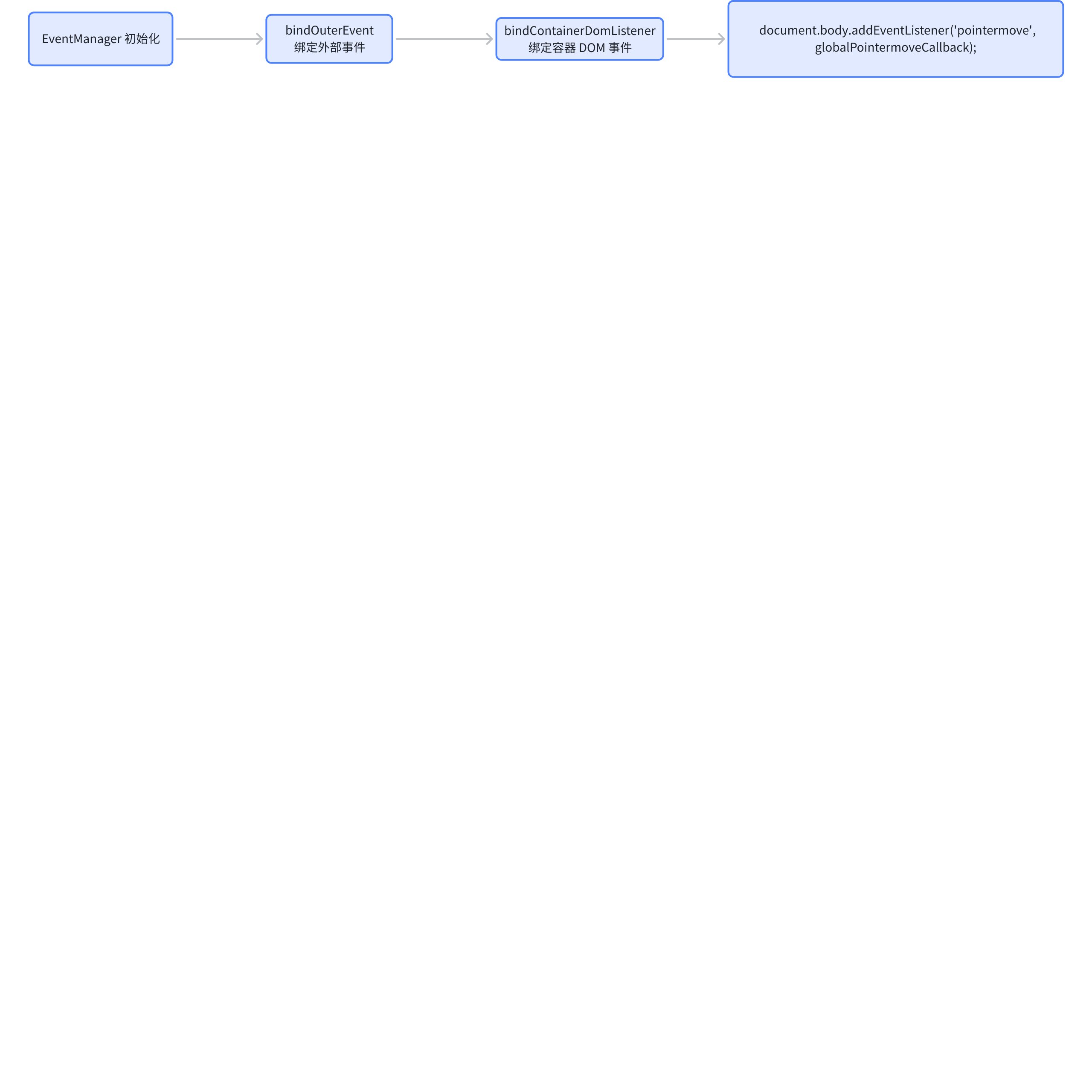
- bindContainerDomListener
ListTable 在 body 处监听了 pointermove 事件,并传入了 globalPointermoveCallback 作为回调。
// packages\vtable\src\event\listener\container-dom.ts
bindContainerDomListener() {
// ...
document.body.addEventListener('pointermove', globalPointermoveCallback);
}
- globalPointermoveCallback
// packages\vtable\src\event\listener\container-dom.ts function globalPointermoveCallback() { // ... if (stateManager.interactionState === InteractionState.grabing) { if (stateManager.isResizeCol()) { eventManager.dealColumnResize(x, y); if ((table as any).hasListeners(TABLE_EVENT_TYPE.RESIZE_COLUMN)) { table.fireListeners(TABLE_EVENT_TYPE.RESIZE_COLUMN, { col: table.stateManager.columnResize.col, colWidth: table.getColWidth(table.stateManager.columnResize.col) }); } } } // ... }
回调内部会去判断是否处于拖拽列宽的状态,再去调用 dealColumnResize,随后触发业务方配置的回调事件。
列宽实时更新机制
ListTable 在调整列宽的时候为什么会这么丝滑,主要的处理逻辑还是在 dealColumnResize 中。而dealColumnResize 的执行,实际上是执行了 updateReizeColumn。

列宽更新流程
更新列宽主要涉及到三个功能函数
- updateReizeColumn(packages\vtable\src\state\resize\update-resize-column.ts)
- updateResizeColForColumn(packages\vtable\src\state\resize\update-resize-column.ts)
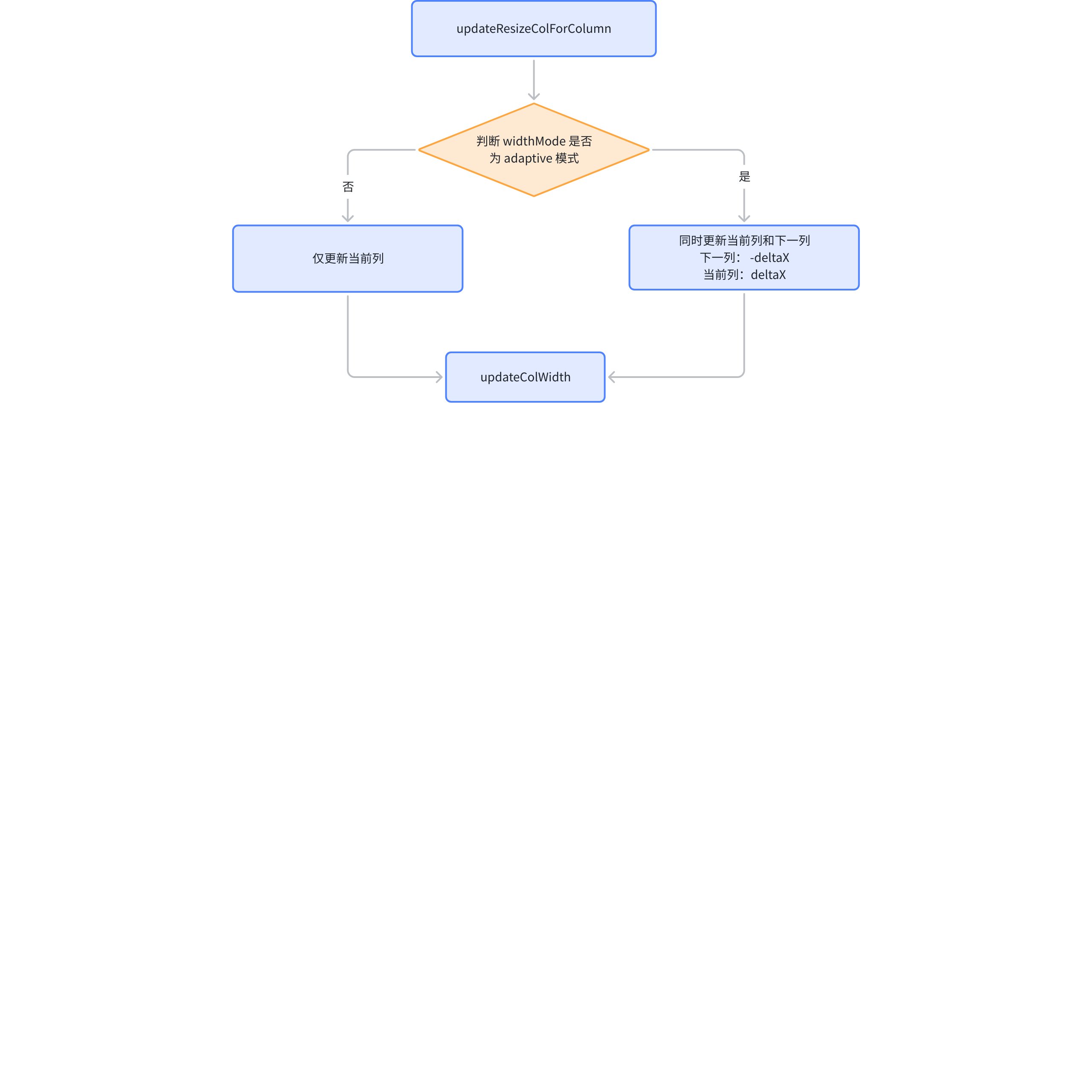
- updateColWidth (packages\vtable\src\scenegraph\layout\update-width.ts)

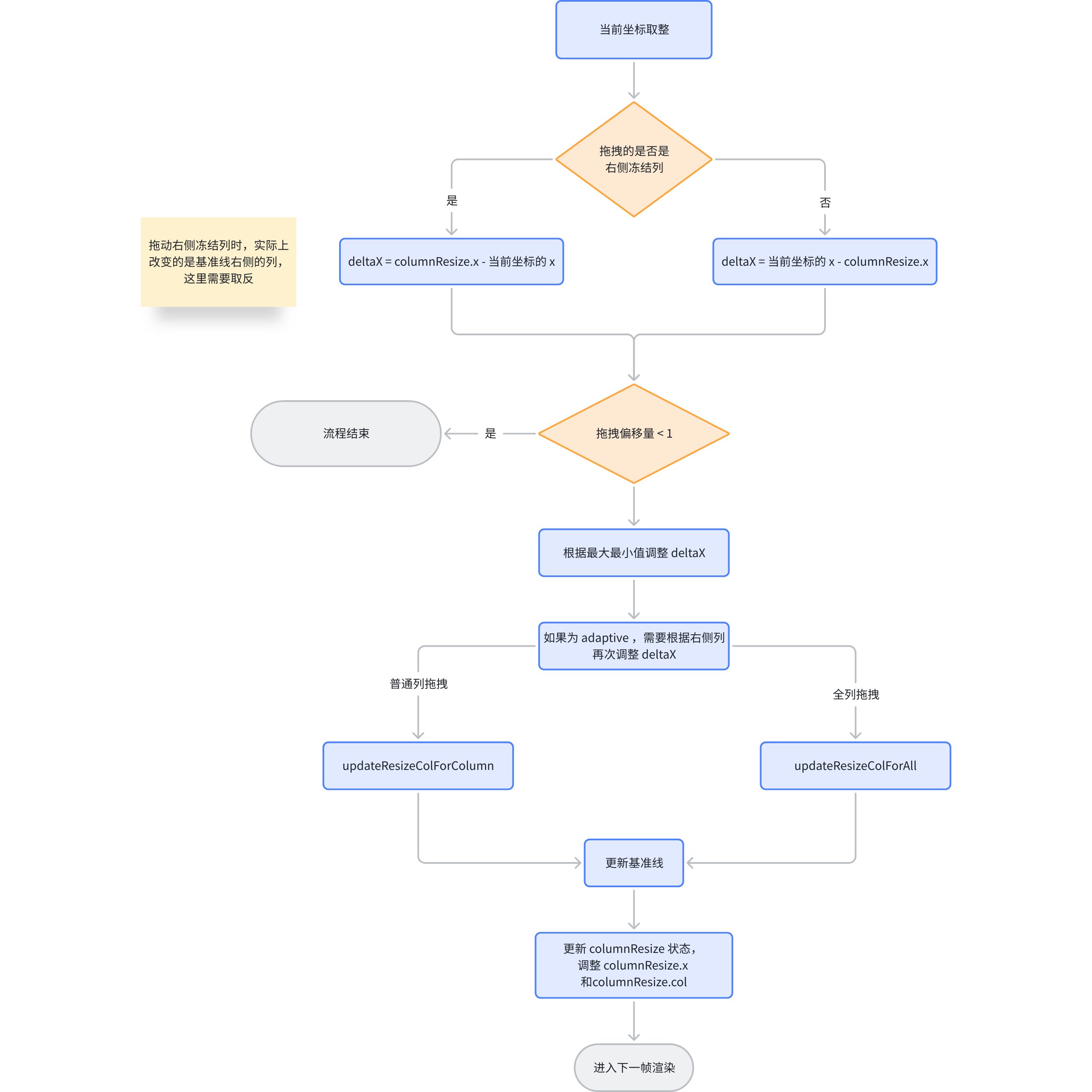
自适应模式下的特殊处理
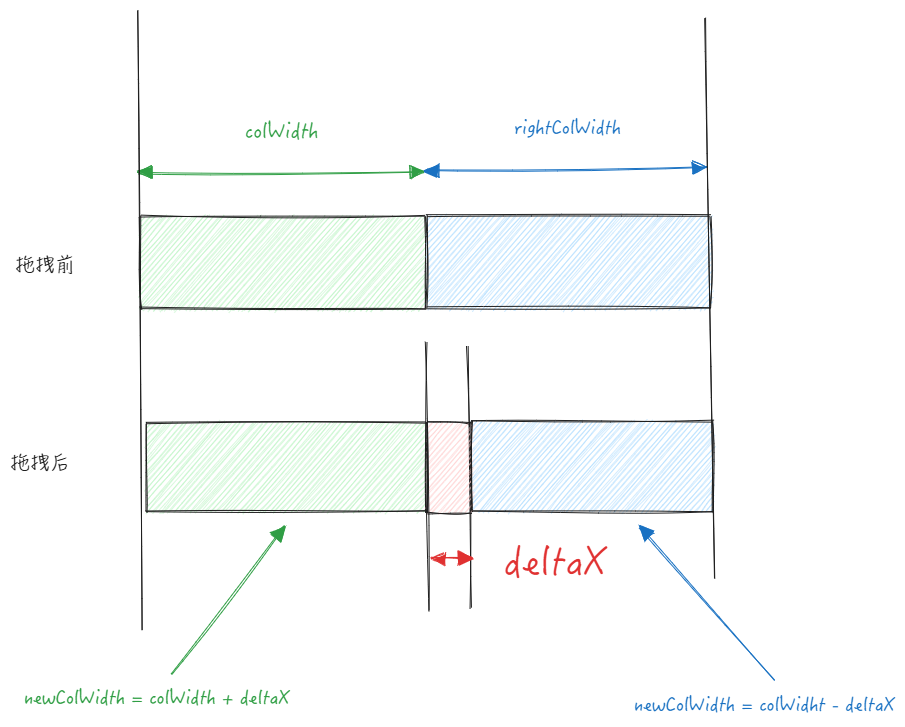
基本表格可以通过 widthMode: 'adaptive' 开启自适应模式,在这种情况下,表格的长度是固定的,不能单独说只去更新一个列,而是基准线两侧的列都需要更新。
假设用户向右拖动了基准线,拖动的偏移量为 deltaX,对于左侧的列来说就是 deltaX,而对于右侧列来说就是 -deltaX
// packages\vtable\src\state\resize\update-resize-column.ts function updateResizeColForColumn(detaX: number, state: StateManager) { // ... state.table.scenegraph.updateColWidth(state.columnResize.col, detaX); state.table.scenegraph.updateColWidth(state.columnResize.col + 1, -detaX); // ... }
拖拽完成
拖拽完成监听的是 pointerup 事件,由于图表在拖拽的过程中已经更新了,所以在拖拽完成的时候,需要做的事情不是很多。主要是做些将状态恢复到默认值之类的操作,具体包括:
-
恢复 stateManager.columnResize 状态
-
更新 interactionState 为默认值
stateManager.updateInteractionState(InteractionState.default);
-
隐藏基准线
-
触发 RESIZE_COLUMN_END 事件
// packages\vtable\src\event\listener\table-group.ts table.scenegraph.tableGroup.addEventListener('pointerup', (e: FederatedPointerEvent) => { //... if (stateManager.interactionState === 'grabing') { stateManager.updateInteractionState(InteractionState.default); if (stateManager.isResizeCol()) { endResizeCol(table); } // ... });
整体流程

列拖拽换位
配置
业务方可以通过 dragHeaderMode 配置开启拖拽表头换位,不过对于拖拽表头换位,只限定同一层级下,不允许跨层级进行拖拽。
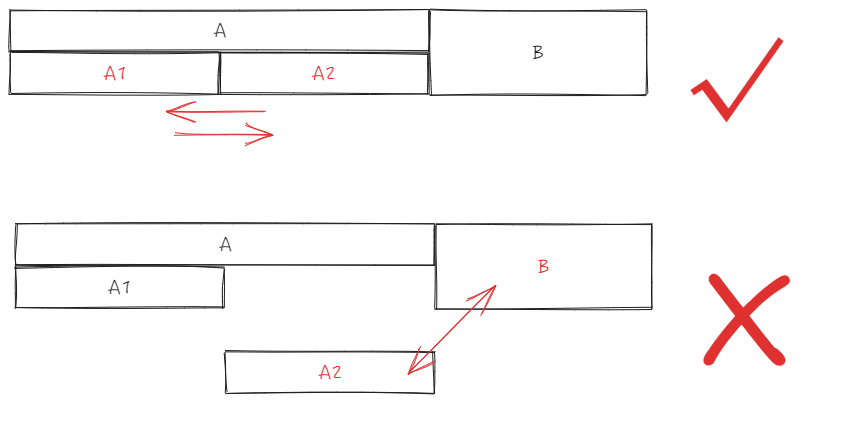
拖拽监听
拖拽换位的监听跟拖拽调整列宽的监听一样,都是监听的 pointerdown 事件。
不过在该回调中,会去优先判断是否命中 拖拽调整列宽,避免影响到 拖拽列宽事件。
// packages\vtable\src\event\listener\table-group.ts
table.scenegraph.tableGroup.addEventListener('pointerdown', (e: FederatedPointerEvent) => {
//...
*// 处理column mover*
if (eventManager.chechColumnMover(eventArgsSet)) {
stateManager.updateInteractionState(InteractionState.grabing);
return;
}
//...
}
- chechColumnMover
// packages\vtable\src\event\event.ts chechColumnMover(eventArgsSet: SceneEvent): boolean { const { eventArgs } = eventArgsSet; if ( eventArgs && this.table._canDragHeaderPosition(eventArgs.col, eventArgs.row) ) { this.table.stateManager.startMoveCol(...); return true; } return false; }
是否进入拖拽
由于拖拽列换位的逻辑特别复杂,所以对于是否进入拖拽的判断会很严格,下图展示了是否进入列拖拽换位的逻辑判断:
- _canDragHeaderPosition(packages\vtable\src\core\BaseTable.ts)
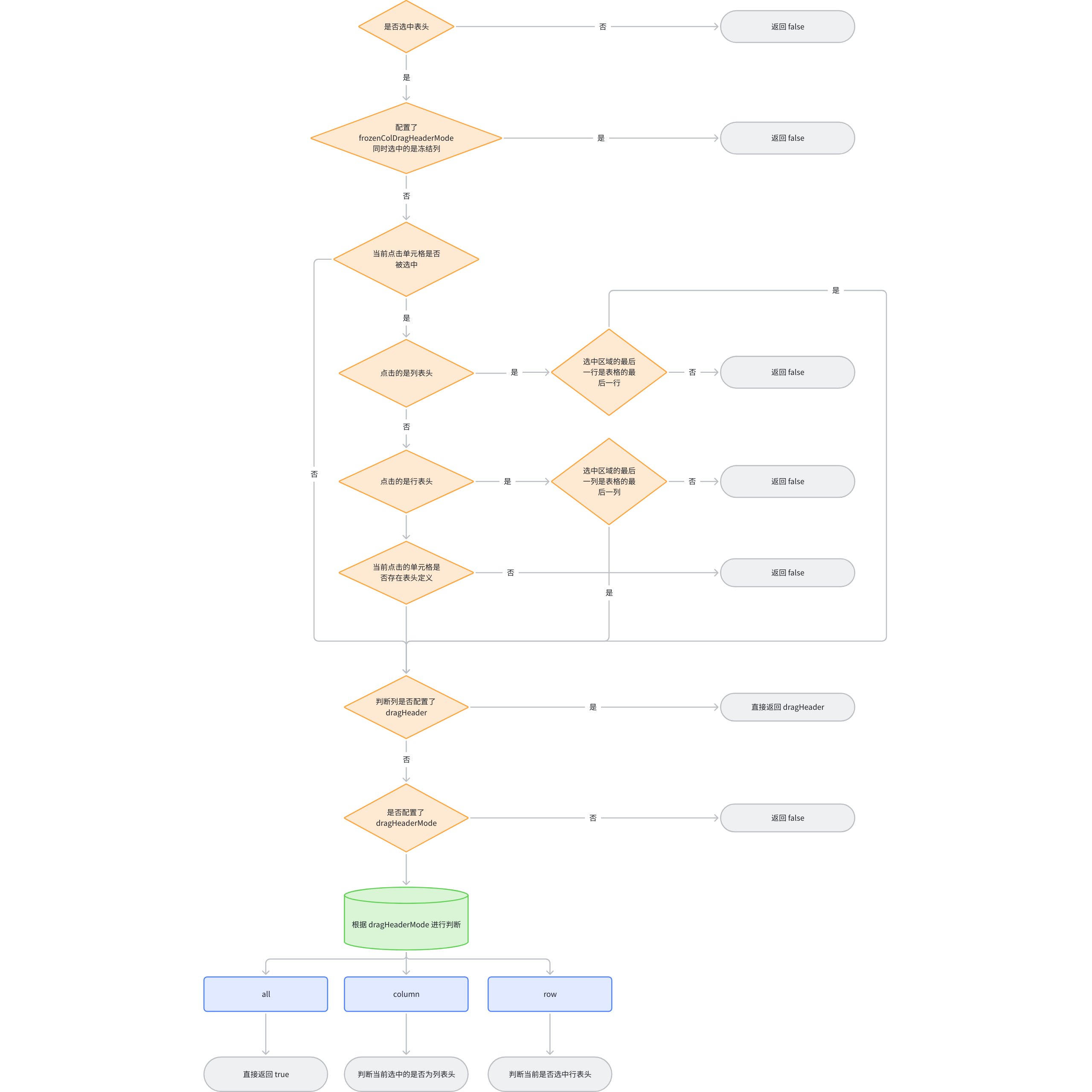
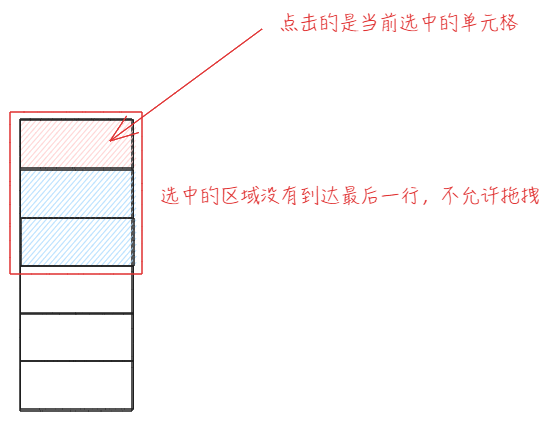
内部有个特殊的判断,如果当前配置的 headerSelectMode 为 'cell' 或者 选中多行情况下范围不包括整列 的情况下,不允许进行拖拽。加上这条判断主要是解决拖拽选中多个表头和拖拽列这两个交互之间的冲突。
初始化拖拽过程
- startMoveCol (packages\vtable\src\state\cell-move\index.ts)
当确定为拖拽列事件的时候,内部会去做三件事:
-
更新 stateManage.columnMove 状态,记录当前拖拽的起始行列号,更新 moving 为 true;
-
展示当前拖拽调整顺序组件
-
清空选中状态
拖拽有效性
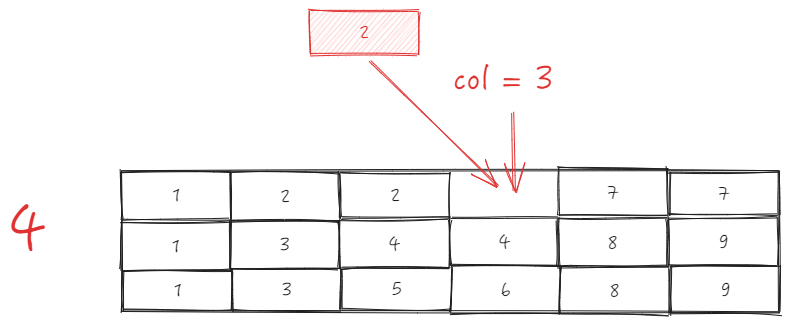
前置场景
假设我们有一个3行6列的表头
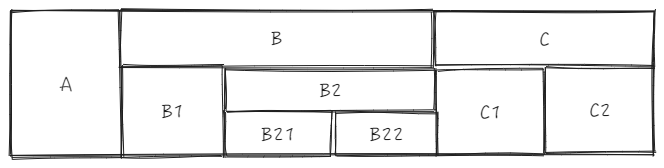
ListTable 中维护了一份 _headerCellIds 在 LayoutMap 模块(表格布局模块) 中,上面的表头对应的 _headerCellIds 长这样:
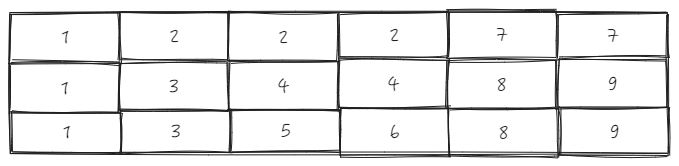
换位规则
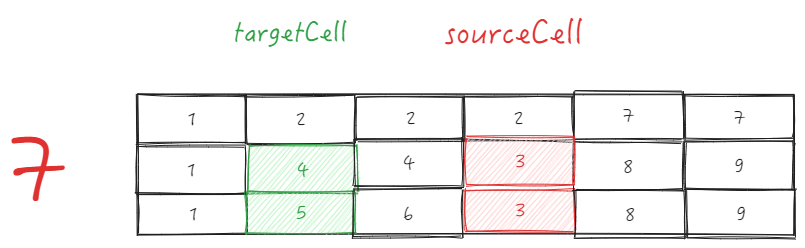
前面提到了,拖拽开始时会去记录 sourceCol ,在拖拽过程中也会实时的获取 targetCol。ListTable 内部主要是去判断二者的父级 ID 是否一致来决定是否可以进行换位。
关于这部分的核心逻辑,位于 layoutMap.canMoveHeaderPosition 中:
// packages\vtable\src\layout\simple-header-layout.ts
canMoveHeaderPosition(source: CellAddress, target: CellAddress): boolean {
// ...
const sourceTopId = this.getParentCellId(source.col, sourceCellRange.start.row);
const targetTopId = this.getParentCellId(target.col, sourceCellRange.start.row);
return sourceTopId === targetTopId;
// ...
}
例如:
- sourceCell 为 B1 ,targetCell 为 B2,直接使用 _headerCellIds 获取父ID
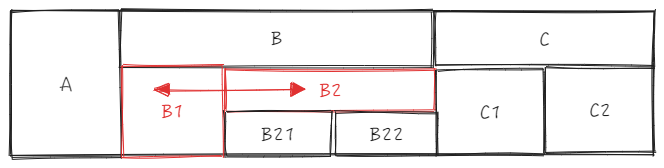
- sourceTopId:
B1 为 sourceCell , col 为 1 , row 为 1, 整体单元格 sourceCellRange 为
start = {col: 1, row: 1} end = {col: 1, row: 2}
根据 source.col = 1 和 sourceCellRange.start.row = 1 获取父 ID 为 2,sourceTopId = 2
- targetTopId:
B2 为 targetCell , col 为 3 ,row 为 1,
根据 target.col = 3 和 sourceCellRange.start.row = 1 获取父 ID 为 2,targetTopId = 2
-
二者 ID 一样,可以进行换位
-
sourceCell 为 B2 ,targetCell 为 C1,直接使用 _headerCellIds 获取父ID
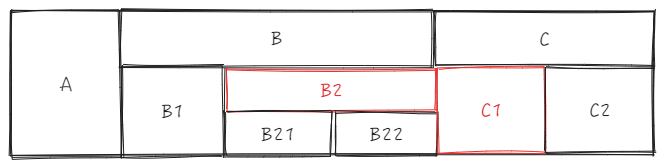
- sourceTopId:
B2 为 sourceCell,col 为 2, row 为 1,sourceCellRange 为
end = {col: 3, row: 1} start = {col: 2, row: 1}
根据 source.col = 2 和 sourceCellRange.start.row = 1 获取父 ID 为 2,sourceTopId = 2
- targetTopId:
C1 为 targetCell,col 为 4 ,row 为 1
根据 target.col = 4 和 sourceCellRange.start.row = 1 获取父ID 为 7,targetTopId = 7
- 二者 ID 不同,禁止换位
可以很明显的看到,进行换位的时候行号都是使用的起始单元格的行号来进行判断的,这是因为默认了拖拽只会发生在同一层级,所以在进行拖拽的过程中,理论上发生改变的只有 col。
_headerCellIds 缓存的目的
layoutMap 中维护了一份 _headerCellIds,其中一部分原因是为了更方便的获取各个节点之间的关系,比如说获取父级节点的时候,假如当前单元格的路径为 _headerCellIds[row][col],那么获取父级 ID 便可直接使用_headerCellIds[row - 1][col] 来获取
拖拽过程
与拖拽调整列宽的回调不同,列拖拽换位的样式更新是在 tableGroup 的 pointermove 事件回调里去做的。而实际上的更新是在 pointerup 事件中。
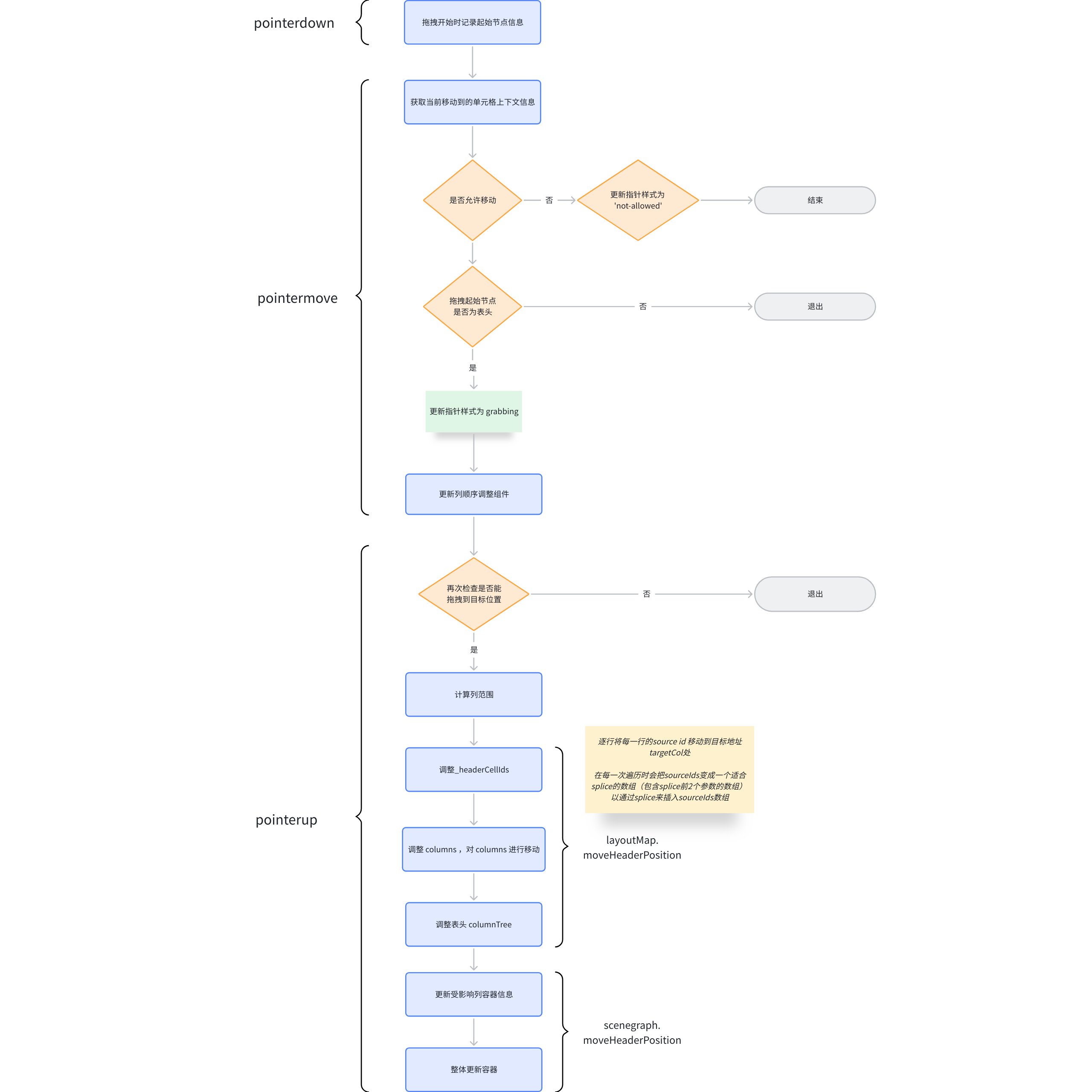
_headerCellIds 更新机制
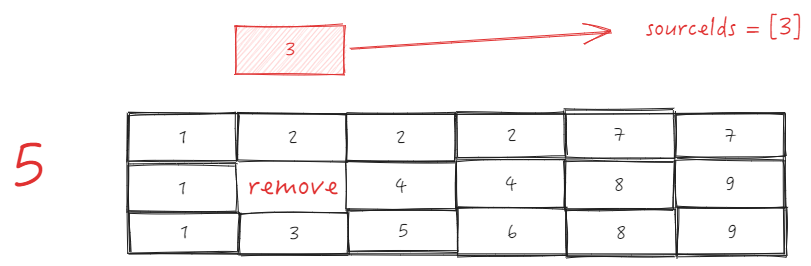
在拖拽事件完成时,会去动态更新 _headerCellIds, 这块的更新逻辑还是比较复杂的,我们以 B1 -> B2 的来进行举例,看下是如何完成 _headerCellIds 的更新的。
- 首先根据 sourceCellRange 获取起始单元格包含的列数 sourceSize;
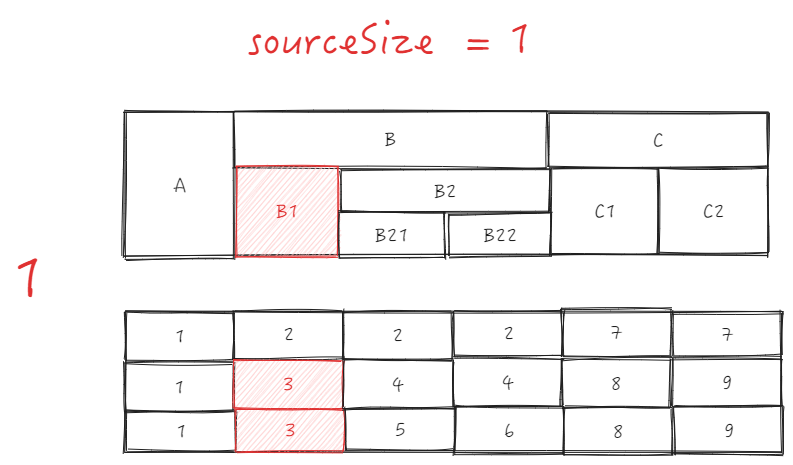
- 获取插入目标地址的列 targetIndex ,这里要分两种情况:
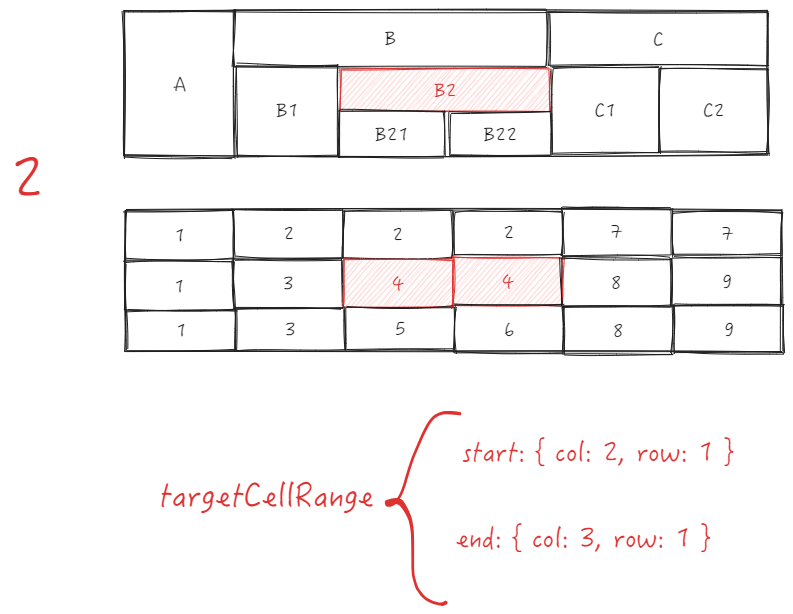
-
目标列在起始列的左边,targetIndex = targetCellRange.start.col;
-
目标列在起始列的右边,targetIndex = targetCellRange.end.col - sourceSize + 1;
现在这种情况下 targetIndex = 3 - 1 + 1 = 3;
-
逐行遍历 _headerCellIds
-
第一行:
-
_headerCellIds 第一行,从 sourceCellRange 的开头的列,删除 sourceSize 的长度,并将删除的元素作为 sourceIds
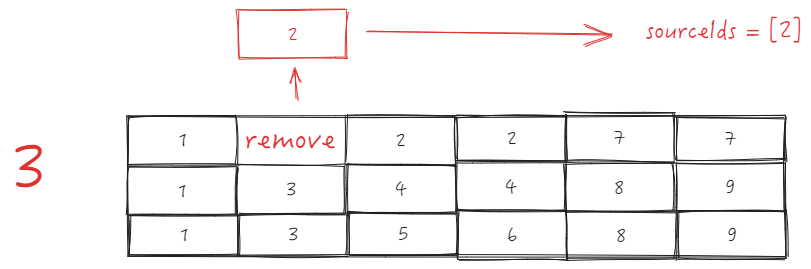
- 随后往 sourceIds 前插入 0 和 targetIndex;
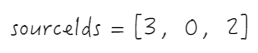
- 调用
Array.prototype.splice.apply(this._headerCellIds[row], sourceIds);等同于this._headerCellIds[row].splice(3, 0, 2),这一步完成后的 _headerCellIds 为
抽象到图表中,实际上等于先将 sourceIndex 之后所有的单元格向前移动,再将起始单元格移动到 targetIndex 处
-
第二行
-
抽出 sourceIds
- 插入 0 和 targetIndex
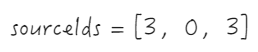
- 将 sourceIds 插入到 targetIndex
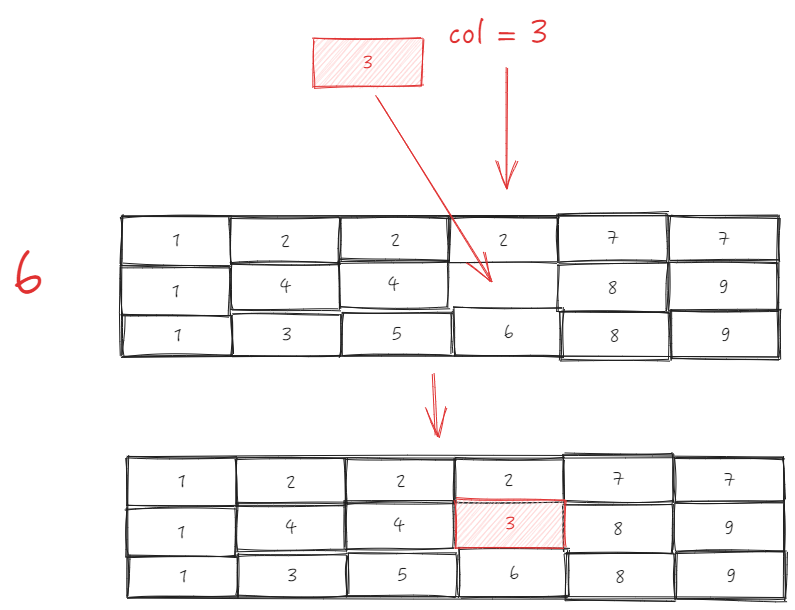
- 第三行同理,更新完后的 _headCellIds 长这样,至此关于拖拽列换位数据索引部分的调整已经完成了。
整体大致流程

表格滚动
需求背景
原生的表格组件库能够直接使用浏览器自带的滚动效果,而对于 Canvas 来说,并不会自动去生成滚动条,同时也没有对应的滚动逻辑,更不用说去像原生 DOM 一样去做虚拟滚动效果。所有关于滚动的效果都需要去手动计算,下面来看下 ListTable 中是如何通过监听 Canvas 事件来实现滚动效果的。
滚动方案
ListTable 支持两种滚动方式,分别是拖拽滚动条和滚轮滚动,这两种滚动本质上都是相同的,不同的地方在于触发点:
滚轮滚动
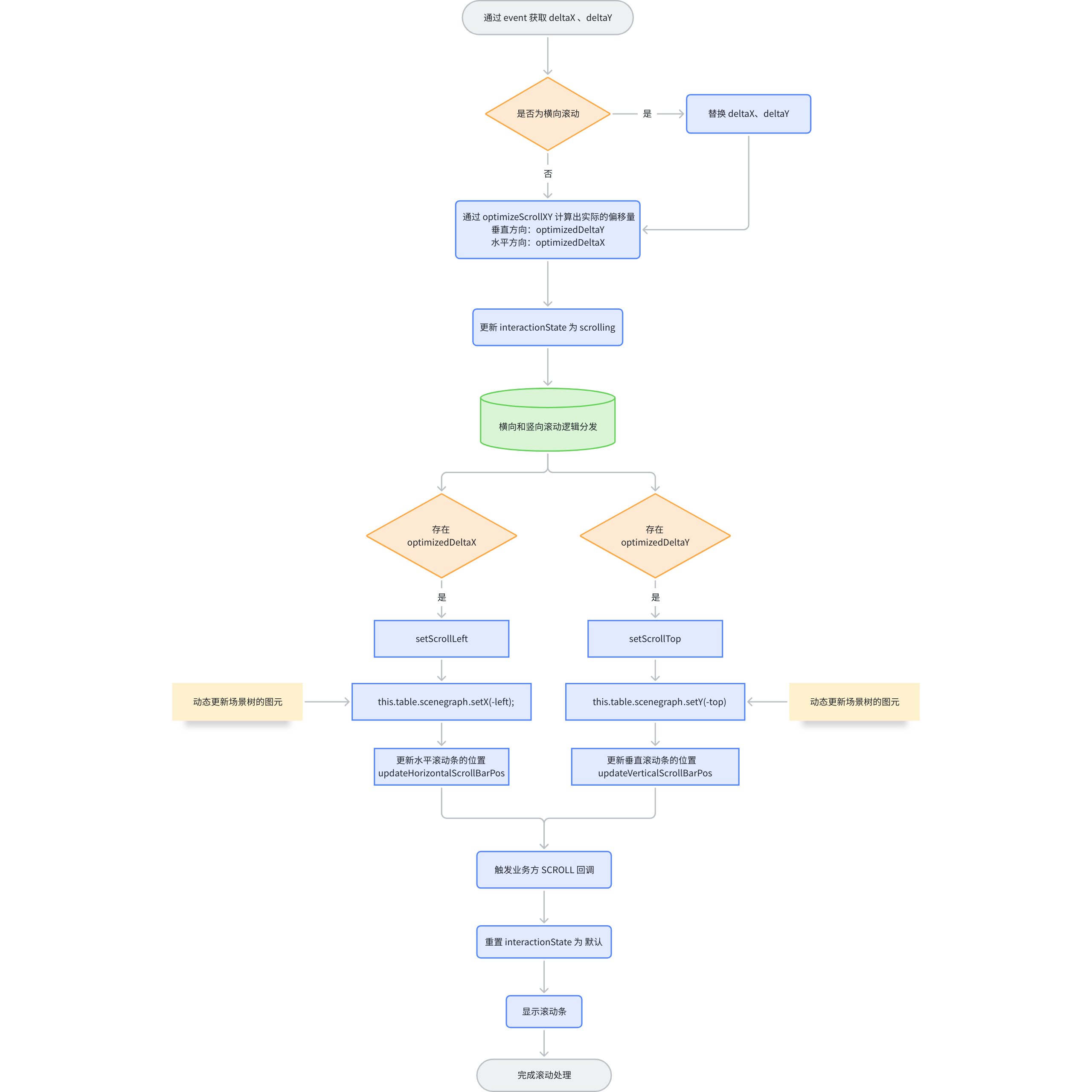
滚轮滚动依托于 Stage 提供的 wheel 事件,在滚动时能够获取到当前滚动的偏移量,之后再在滚动的过程中进行渐进式加载表格图元。
这里是关于滚轮滚动的一个大致流程:
拖拽滚动条
滚动条使用的是 VRender 提供的 ScrollBar 组件,监听 scroll 事件来完成滚动的逻辑;在拖拽过程中的处理与滚轮滚动的逻辑大体相同,核心都是通过 this.table.scenegraph.setY 来完成场景树的渐进加载;
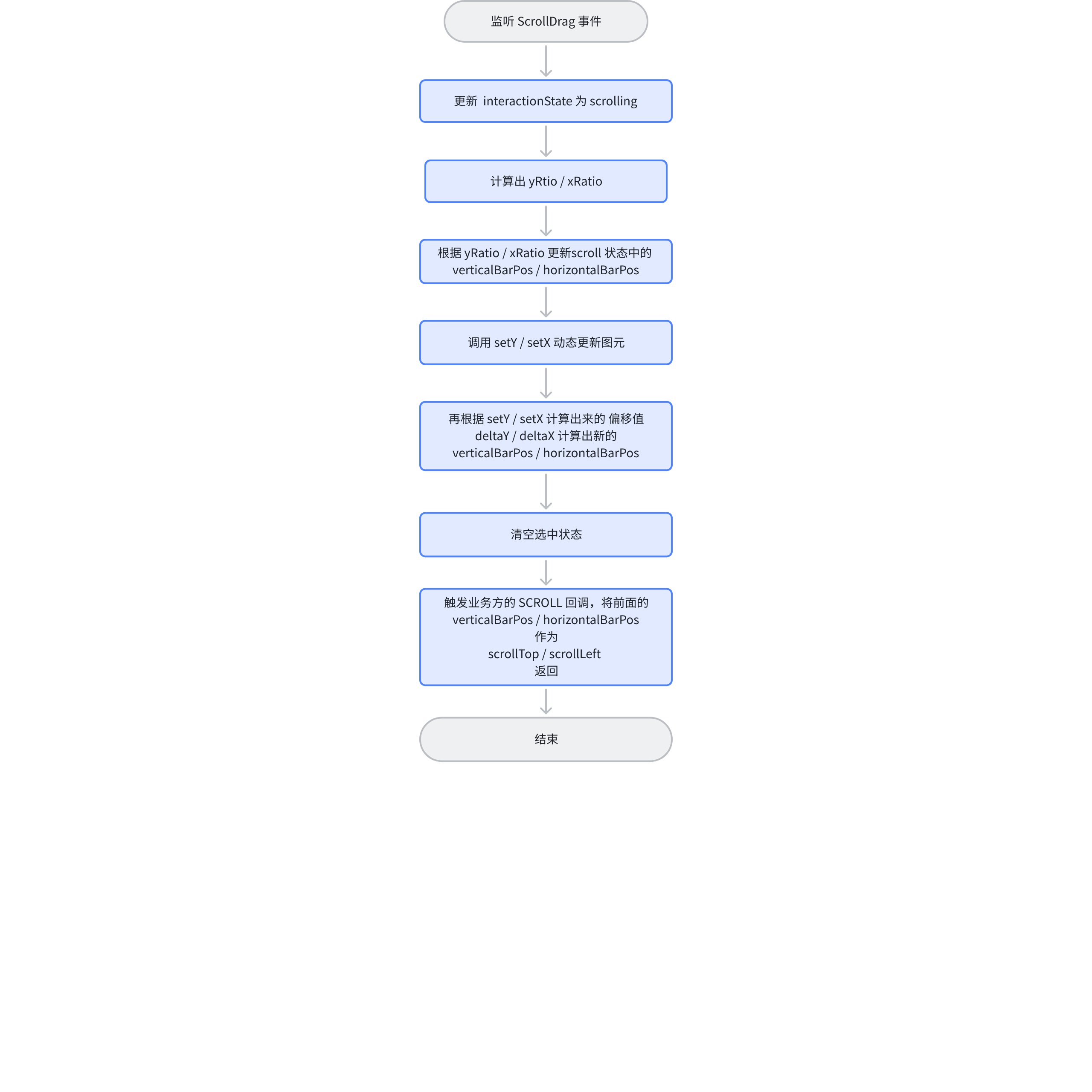
由于是用户手动拖动滚动条来触发,所以不需要去更新滚动条的位置了,而且相对应的只会同时存在一个方向,在进入逻辑前就已经知道对应的方向了。
滚动偏移量优化
在滚轮滚动的过程中,出现了这么一个函数 optimizeScrollXY,他的作用主要是用于优化滚动方向,将接近水平或垂直的滚动转换为单一方向的滚动,避免斜向滚动带来的干扰。
公式
-
ANGLE = 2 ,定义为方向判断的斜率阈值
-
通过
x ``/ y获得斜率 angle -
优化后的 deltaX = angle <= 1 / ANGLE ?0 : x
-
优化后的 deltaY = angle > ANGLE ? 0 : y
核心处理
-
当
x/y的绝对值小于等于 0.5(即 1/ANGLE)时,视为垂直滚动,将水平增量清零 -
当
x/y的绝对值大于 2(即 ANGLE)时,视为水平滚动,将垂直增量清零 -
中间角度则保留原始增量(视为斜向滚动)
简单来说,就是斜率在 0.5 ~ 2 之间的,才会保留原始值,否则都会重置为单一方向。
案例
我们从下面几个案例分析来看下,optimizeScrollXY 是如何进行优化的。
- 明显垂直滚动(y方向增量远大于x)
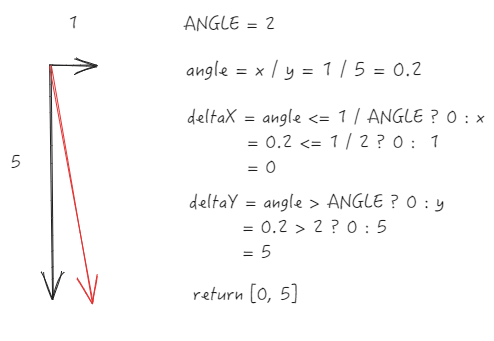
重置为垂直滚动
- 明显水平滚动(x方向增量远大于y)
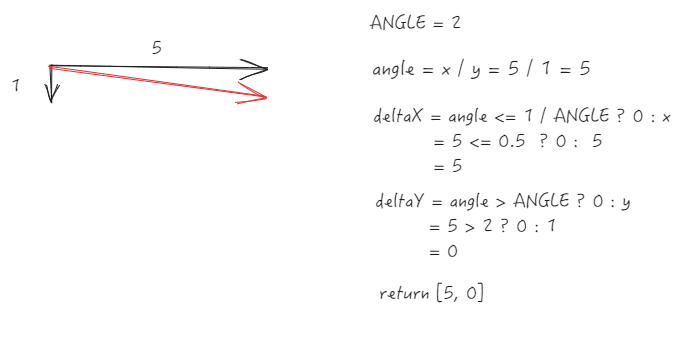
重置为水平滚动
- 45 度斜角滚动(x/y=1)
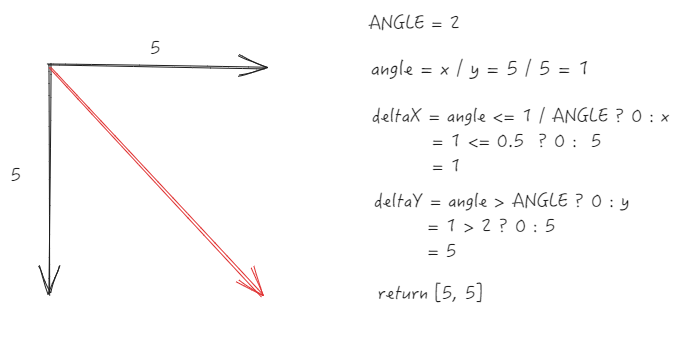
保留原始值
渐进式加载
由于 ListTable 滚动的流畅度表现在帧数上面,在一秒内能展示的帧数越多,表格的滚动就越流畅。而想要提升帧数,就必须在滚动时对数据处理做优化,确保能有更多帧去重新渲染图表,为此 ListTable 对于滚动做了渐进式加载,在滚动的时候,并不是简单调整 x,y 坐标,而是通过动态调整单元格来实现滚动。接下来来看下 ListTable 具体是如何去实现的:
入口文件
前面提到了 setY 和 setX 方法,这两个方法是表格实现滚动的核心逻辑,两个方法的入口在 scenegraph 模块中,这里实际上都是调用了 SceneProxy 中的 setX 、setY 方法。
// packages\vtable\src\scenegraph\scenegraph.ts
*/***
* * @description: 设置表格的x位置,滚动中使用*
* * @return {*}*
* */*
setX(x: number, isEnd = false) {
this.table.scenegraph.proxy.setX(-x, isEnd);
}
*/***
* * @description: 更新表格的y位置,滚动中使用*
* * @param {number} y*
* */*
setY(y: number, isEnd = false) {
this.table.scenegraph.proxy.setY(-y, isEnd);
}
SceneProxy
关于 SceneProxy 模块,是 SceneGraph 的一个子模块,是在 SceneGraph 初始化的时候创建的。该模块主要负责了初始化场景树最大行列数的计算、场景树的渐进加载、首屏分组创建的逻辑。
我们以 setY 为例,这里是 setY 的流程图:
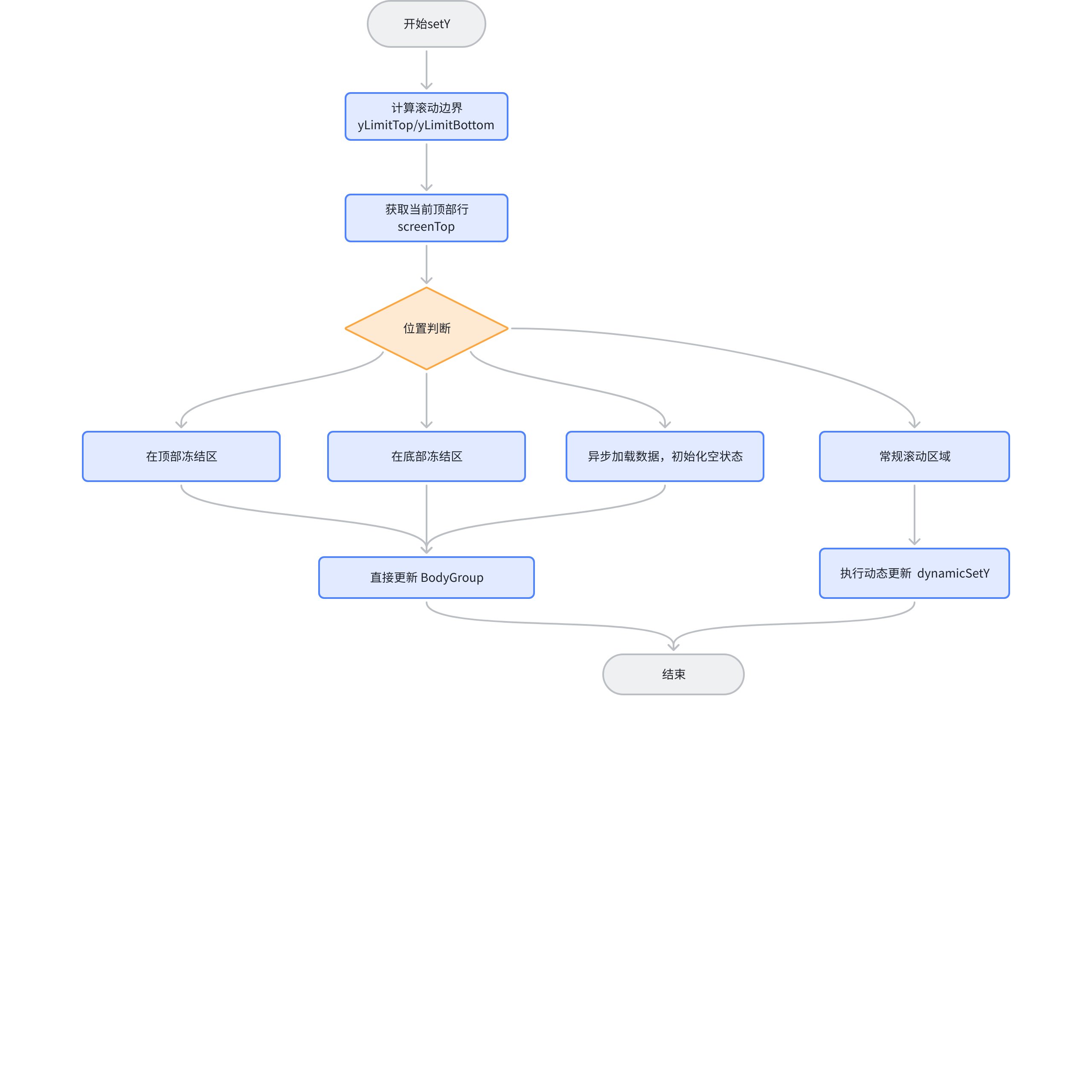
其中 dynamicSetY 才是渐进式更新的核心逻辑。
场景树动态更新
- packages\vtable\src\scenegraph\group-creater\progress\update-position\dynamic-set-y.ts
渐进式加载的核心逻辑位于 dynamicSetY 中,接下来我们来看下 dynamicSetY 中做了什么。
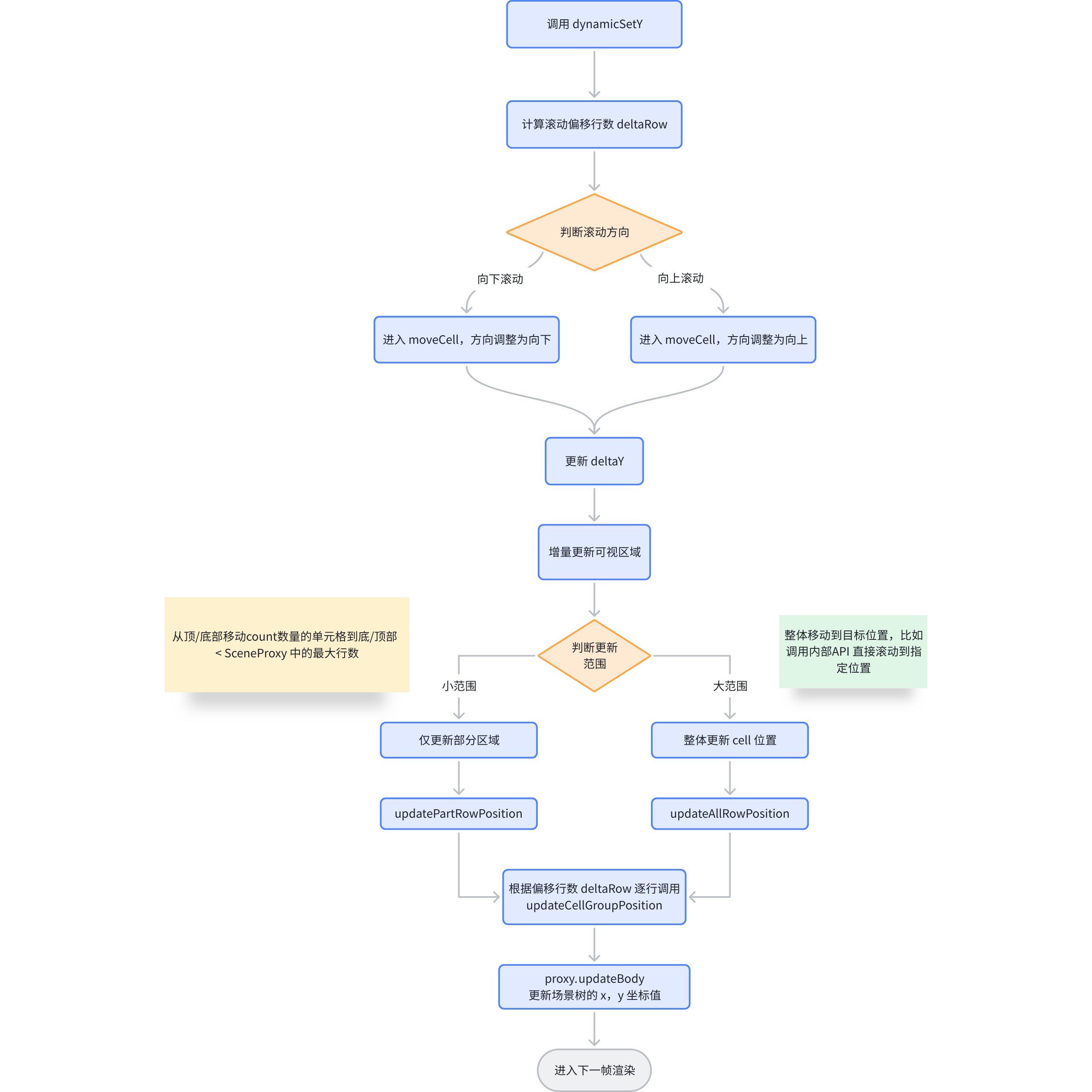
核心实现原理
在ListTable 中也存在着单元格复用的操作,dynamicSetY 的前置流程主要是确定了更新的范围,关于实际的更新逻辑位于 updateCellGroupPosition 中。
我们以向下滑动来举例,ListTable 中会先将第一个单元格取出来,更新 CellGroup 的y值,再将该单元格塞入到 ColGroup 的最后一个,如果前面计算出了需要更新的单元格数量,那就会重复进行多次该操作。
通过该操作能够避免频繁的创建单元格,只需要更新下单元格的位置即可。
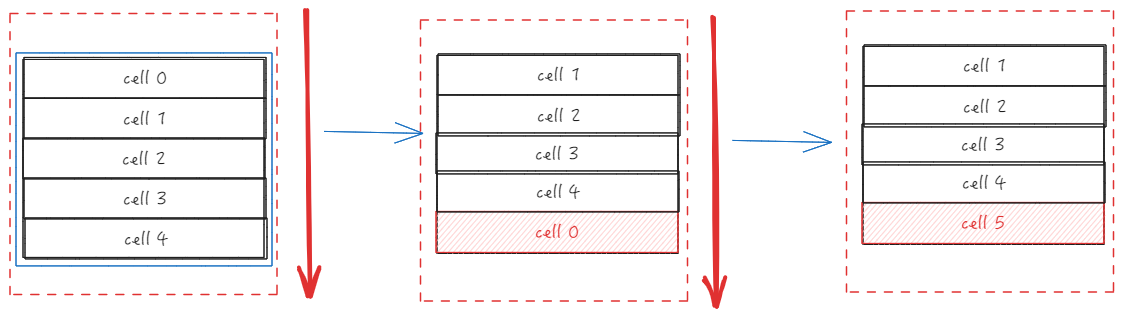
总结
本文从 ListTable 的模块入手,讲述了 ListTable 中大部分功能和交互的底层实现逻辑。
从上面的几个结构分析中,可以看出 ListTable 做了很多的性能优化,包括数据的索引存储;分组算法中对于各个不同的分组做映射表,降低节点插入的时间复杂度;表头的数据索引存储,降低对表头进行处理的时间复杂度;滚动时场景树的渐进加载等。
本文档由以下人员提供
taiiiyang( https://github.com/taiiiyang)